Model Optimizer活用の画像分類
2020/06/11

「AI CORE XスターターキットとOpenVINO™ですぐに始めるディープラーニング推論」シリーズの11回目記事です。
このシリーズは、「ディープラーニングとは何か」から始まり、「各種ツールの使い方」「プログラミング基礎」「プログラミング応用・実践」までをステップバイステップでじっくり学び、自分で理解してオリジナルのAIアプリケーションが作れるようになることを目指しています。

第11回目はOpenVINO™のModel Optimizerを活用してディープラーニング画像分類を行います!
目次
- Model Optimizerとは
- Model Optimizerの使い方
- Model Optimizer実行
- 分類ラベルのリストを入手
- ディープラーニング画像分類
- ベスト5で画像分類
- リアルタイム画像分類
Model Optimizerとは
これまではインテルが用意した学習済みモデルを使ってきましたが、Model Optimizerを使うと他のフレームワークでの学習済みモデルをOpenVINO™ツールキットで使うことができるようになります。
具体的にはIR形式というOpenVINO™ツールキットで扱える形式に変換します。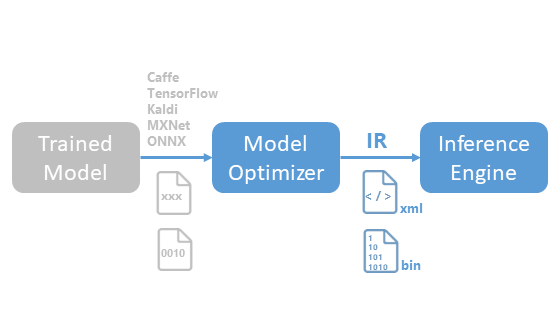
実際には単に変換するだけでなく、モデルの最適化も行われます。
例:dropout層など推論時に必要ない層を取り除いて推論時間を短縮
最適化は意識しなくても自動的に行われますので、ここでは変換の手法をメインに説明してゆきます。その前に、まずは「フレームワーク」や「モデル」について簡単に説明します。
対応フレームワーク
ここで言う「フレームワーク」とはディープラーニング学習を行うためのツールのようなものです。それぞれのフレームワークは学習後にモデルを生成しますが、それぞれで形式が異なります。Model Optimizerで変換できる形式に対応しているフレームワークは次の通りです
- Caffe
- TensorFlow
- Kaldi
- MXNet
- ONNX
ここに記載のないフレームワークは対象外という訳ではありません。
ONNXは共通のモデル形式です。ONNX形式に変換することが出来れば、ここに書いていないフレームワークも対応可能です。
一方でフレームワークに対応していたとしても、問題なく変換するにはOpenVINO™にてサポートされている層(レイヤー)である必要がありますので、特殊な学習済みモデルを扱う場合はご注意ください。詳細はOpenVINO™ツールキットの公式ドキュメントを参照してください
今回の実行例では Caffe モデルを取り扱います
画像解析タスク
ディープラーニングの画像解析タスクにもいくつか種類があります。
- Classification
- Object detection
- その他(Segmentationなど)
この辺は第1回目のディープラーニング概要で説明した内容ですので、忘れた方はもう一度見てみて下さい。
今回はClassificationを取り扱います
Caffeモデル
CaffeのClassification modelsにも様々な種類があります
- AlexNet
- VGG
- SqueezeNet
- ResNet
- Inception
- CaffeNet
- MobileNet
- SE-Resnet, SE-ResNeXt
これらのモデルに違いについて簡単に説明します
主に高精度化を目指しているモデルと、軽量化を目指しているモデルの2種類に分かれます。
高精度化モデル
画像分類のモデルの多くが2012年~2017年に行われた大規模な画像認識の競技会ILSVRCで生まれています。
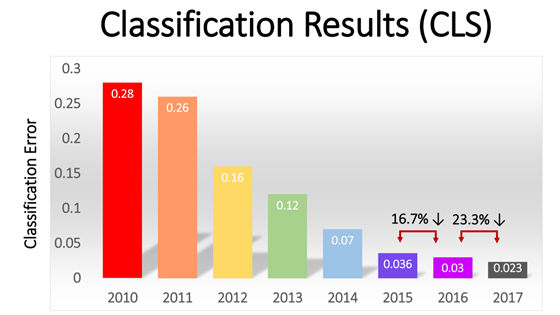
画像引用元:IMAGENET Large Scale Visual Recognition Challenge(ILSVRC)2017
上のグラフはILSVRCでの精度向上の推移を表しています。縦軸が「分類の誤り」ですので、徐々に精度が向上しているのが分かると思います。特に2012年に大きく精度が向上しているのが分かると思いますが、ここからディープラーニングの活躍が始まりました。それぞれの年度ごとの優勝モデルを以下の表にまとめています。先ほどのCaffeモデルの中に挙がっていた名前です。
| ILSVRC | 優勝モデル | 備考 |
|---|---|---|
| 2012 | AlexNet | CaffeNetはこれに近い |
| 2013 | 省略 | AlexNetに近い |
| 2014 | Inception(GoogLeNet) | 2位がVGG |
| 2015 | ResNet | この辺から人間の眼の精度超え |
| 2016 | 省略 | 既存モデルの組合せ |
| 2017 | SENet | SE-Resnet, SE-ResNeXtはこれに近い |
詳しい内容が知りたい方はこちらのサイトを参照してください。
軽量化モデル
先程の図の2015年以降を見ると分かりますが、数字がかなり小さくなっていて非常に精度が高い状態になりました。そして2017年をもってILSVRCは終了となりました。
高精度化の次に注目されたのが軽量化です。いくら高精度でも処理時間が長いのは困ります。特にカメラでリアルタイムに画像分類する際は、推論処理時間がかなり効いてきます。超高性能なPCを使わなくてもスマホ等でもそこそこの精度で、短時間で推論処理できるようにするのが軽量化の狙いです。
最初に挙げたリストの中で、先程の表に登場していない以下のモデルが軽量化を目指したモデルです
- SqueezeNet
- MobileNet
モデルに対する計算量GFlopsとパラメータ数mParamsの表を以下に示します。
こちらから1部を抜粋しています。特に計算量であるGFlopsが大きい程、推論処理時間も大きくなります。
入力画像のサイズなどの条件が異なるので、この表では一概にどれが良いのかは比較できませんが、軽量の目安としたいと思います。同じモデルでも、バージョンが違ったり設定が異なる派生モデルが多数存在します。
| Model Name | GFlops | mParams |
|---|---|---|
| resnet-50 | 6.996 | 25.53 |
| se-resnet-50 | 7.775 | 28.061 |
| se-resnext-50 | 8.533 | 27.526 |
| mobilenet-v1-1.0-224 | 1.148 | 4.221 |
| mobilenet-v2 | 0.876 | 3.489 |
| squeezenet1.0 | 1.737 | 1.248 |
| squeezenet1.1 | 0.785 | 1.236 |
resnetやse-resnet、se-resnextはGFlopsが高いのに比べ、mobilenetやsqueezenetはかなり低いのが分かるかと思います。研究レベルでなく、実用レベルであれば、どれもそれなりに精度はそこそこ高いですので、今回はこの中で最軽量の squeezenet1.1 を扱うこととします
Model Optimizerの使い方
前処理
先に簡単に前処理について説明します
これまでのディープラーニング推論時、カメラ画像をいきなりそのまま処理せず、画像サイズをリサイズするなど要求されたフォーマットに変換していました。これも一種の前処理ですが、この他にも事前に画像の正規化などの前処理を行っている学習済モデルがあったりします。
画像の正規化などの前処理はモデルの中に含ませることが可能で、その場合はソースコードに前処理の記述が不要となります。Model Optimizerではスクリプト実行時にオプション指定することにより実現できます。
実行方法
Model Optimizerの実行方法は2通りあります
- mo.pyスクリプトのみ活用
- Toolスクリプト活用
| 方法 | 対象モデル | ダウンロード | 前処理設定 |
|---|---|---|---|
| mo.pyスクリプト | 任意 | 手動 | 手動 |
| Toolスクリプト | 限定 | 自動 | 自動 |
mo.pyの場合は任意のモデルが対象ですが、手動でダウンロードしたり設定が必要です。
一方のToolスクリプトの場合は限定モデルに限られますが、設定は自動で行われるため簡単です。限定といっても、現状151個の中から選択可能です。
Toolで対象となっているモデルが知りたい方は以下のコマンドで確認できます。
cd /opt/intel/openvino/deployment_tools/tools/model_downloaderpython3 downloader.py --print_all
Model Optimizer実行
では、具体的にModel Optimizerを使ってcaffeで学習済のモデルsqueezenet1.1をダウンロードした後、OpenVINO™で使えるIR形式に変換します。
今回のsqueezenet1.1は限定モデルの中に入っていますので、Toolスクリプトで行いたいと思います。
Toolスクリプトにはdownloader.pyとconverter.pyがあります。
移動
まず、最初にToolスクリプトが使えるディレクトリに移動します。
cd /opt/intel/openvino/deployment_tools/tools/model_downloader
ダウンロード
downloader.pyを使ってsqueezenet1.1をダウンロードします
python3 downloader.py --name squeezenet1.1 --output_dir ~/workspace
今回使用したオプションの説明です
| オプション | 詳細 | 値の例 |
|---|---|---|
| name | ダウンロードしたいモデル名 | squeezenet1.1 |
| output_dir | ダウンロード先のディレクトリ | ~/workspace |
これでworkspaceフォルダに中にpublicフォルダが作られ、その中にsqueezenet1.1ができ、その下にcaffemodelファイルなどが出来ていると思います
変換
今回のAI CORE Xスターターキットにてconverter.pyを実行するにあたり、前後で必要なコマンドがあります。詳細はQuickStartGuideに「Model Optimizer (mo.py)、モデル変換ツール(converter.py) 実行時の注意」という箇所に書いてありますが、ここでは簡潔に手順だけを記します。
実行前に必要なこと
以下のコマンドを打ち込み、一時的に環境を切り替えます
source /opt/intel/openvino/deployment_tools/model_optimizer/venv/bin/activate
以下のように(venv)という表示が出ていればOKです
(venv) aidl@UP-APL01:/opt/intel/openvino/deployment_tools/tools/model_downloader$
実行
converter.pyを使って、IR形式に変換します。自動で前処理(mean_valuesやscale調整)も行われます。実行後、少し時間がかかりますので待ちましょう。
python3 converter.py --name squeezenet1.1 --download_dir ~/workspace --output_dir ~/workspace --precisions FP16
今回使用した各オプションの説明です。
| オプション | 詳細 | 値の例 |
|---|---|---|
| name | 変換したいモデル名 | squeezenet1.1 |
| download_dir | ダウンロードしたディレクトリ | ~/workspace |
| output_dir | 変換後のディレクトリ | ~/workspace |
| precisions | フォーマット指定 | FP16 |
先程のsqueezenet1.1フォルダの下にFP16フォルダが作られて、その中にsqueezenet1.1.binやsqueezenet1.1.xmlなどのファイルが出来ていると思います。これでOpenVINO™で扱えるモデルと重みに変換されました。
実行後に必要なこと
以下のコマンドを打ち込み、環境を元に戻します
deactivate
以下のように(venv)という表示が無くなっていればOKです
aidl@UP-APL01:/opt/intel/openvino/deployment_tools/tools/model_downloader$
これでModel Optimizerの説明は完了です!
後半は、ディープラーニング画像分類について説明してゆきます。
分類ラベルのリストを入手
画像分類モデルは、推論時に入力画像に対してその予測結果を返しますが、例えばcatなど具体的な文字列で返すのではなく 282など数値を返してきます。
数値に対応した実際の文字列は、リストを参照することで得ることができます。
そのリストが synset_words.txt です。このファイルをダウンロードしてworkspaceに置きたいと思います。
まず、以下のコマンドでworkspaceに戻ります
cd ~/workspace
以下のコマンドでダウンロードします。
wget https://raw.githubusercontent.com/HoldenCaulfieldRye/caffe/master/data/ilsvrc12/synset_words.txt
試しにプログラム上で読み込んで表示してみましょうsynset_words.txtを読み込んで282番目の文字列を表示するサンプルプログラムです
以下の内容でpythonを作成して実行してみてください
import numpy as nplabels = npprint()
np.loadtxtを使うとテキストファイルを読み込むことができます。第2引数はデータ型を文字列に、第3引数は区切り文字を改行コード\nに指定という意味です。実行すると以下のように表示されます
n02123159 tiger cat
この後のディープラーニング推論では出力として数値が出てきます。その数値を元にsynset_words.txtから文字列を取り出すことで分類結果が分かります。
ディープラーニング画像分類
ではsqueezenet1.1を使って、ディープラーニング画像分類を行います。
まず入力用の画像を用意します。OpenCV基礎プログラミングで使用したcat.jpgを再び使います

cat.jpgをコピーするか、移動するかして、imageフォルダに入れて下さい
それでは、この画像を推論して分類結果を表示します
以下のソースコードで実行してみてください
import cv2import numpy as np# モジュール読み込みfrom openvino.inference_engine import IENetwork, IEPlugin# ターゲットデバイスの指定plugin =# モデルの読み込みnet =exec_net = plugin# 入力データと出力データのキーを取得input_blob =out_blob =# ラベル読み込みlabels = np# 入力画像読み込みimg = cv2# 入力データフォーマットへ変換img = cv2 # HeightとWidth変更img = img # HWC > CHWimg = np # CHW > BCHW# 推論実行out = exec_net# 出力から必要なデータのみ取り出しout =# 不要な次元を削減out = np# 全て表示print(out)# 出力値が最大のインデックスを得るindex_max = npprint(index_max)# 最大の出力値を表示print()# 最大の出力値であるラベルを表示print()
1000個の値と3つの値が表示されたと思います
2830.47705078n02123394 Persian cat
全体的なプログラムの流れとしては、基本的には landmarksで行った内容とほぼ同じですが、argmaxを使って最大のインデックスを得て処理している点が唯一異なります。
1000個の値(省略) はsynset_words.txtの各行に対する確率値を表しており、全ての値を合計するとほぼ1.0になります
283は一番大きい値が何番目にあるかを示すインデックス番号です(始まりは0から)
0.47705078は1000個の値(省略)において、インデックス番号283の位置にある値です。百分率にすると約47.7%という意味になります
n02123394 Persian catはsynset_words.txtにおいて、インデックス番号283の位置にある文字列です
つまり、入力画像に対するディープラーニング推論結果は、Persian cat(ペルシャ猫)であり、その確率値が47.7%ということになります。
※n02123394は同義語のグループを示すIDなので今回は無視します
ベスト5で画像分類
先程は確率が最も高いNo.1のみを表示していましたが、ベスト5まで表示したいと思います。使用するのはargsortとスライスです。
少し復習します。以下のコードを作って実行してください
import numpy as nplabel =price = nporder = npprint(order)for i in order:print(, )
labelにはフルーツ名が入っていて、それに対応したそれぞれの価格がpriceに入っています。これを高価な順でベスト3に並べていますargsortで昇順にインデックス番号が並び、[::-1]で反転するため降順となり、[:3]で上位から3つの要素のみ切り出しています
peach 500orange 400apple 300
これを先ほどのディープラーニング推論に応用して、確率値が高い順でベスト5まで表示します
import cv2import numpy as np# モジュール読み込みfrom openvino.inference_engine import IENetwork, IEPlugin# ターゲットデバイスの指定plugin =# モデルの読み込みnet =exec_net = plugin# 入力データと出力データのキーを取得input_blob =out_blob =# ラベル読み込みlabels = np# 入力画像読み込みimg = cv2# 入力データフォーマットへ変換img = cv2 # HeightとWidth変更img = img # HWC > CHWimg = np # CHW > BCHW# 推論実行out = exec_net# 出力から必要なデータのみ取り出しout =# 不要な次元を削減out = np# 降順でベスト5のインデックスを抽出index_order = np# ベスト5のインデックスについてラベルと値を表示for index in index_order:print(, )
n02123394 Persian cat 0.47705078n02123045 tabby, tabby cat 0.25561523n02127052 lynx, catamount 0.037994385n04074963 remote control, remote 0.034576416n03793489 mouse, computer mouse 0.0335083
このような表示になっていると思いますが、見やすいように表にしてみました
| label | out | 分類結果(日本語) | 確率値(百分率) |
|---|---|---|---|
| Persian cat | 0.47705078 | ペルシャネコ | 47.7% |
| tabby, tabby cat | 0.25561523 | トラネコ | 25.6% |
| lynx, catamount | 0.037994385 | オオヤマネコ | 3.8% |
| remote control, remote | 0.034576416 | リモコン | 3.6% |
| mouse, computer mouse | 0.0335083 | PCのマウス | 3.4% |
このようにディープラーニングは「これは猫です」という結果ではなく、数値で結果を返してくるという意味が分かったかと思います。他の画像でも色々と試してみて下さい
リアルタイム画像分類
では、最後にUSBカメラを使ったリアルタイム推論を行います。
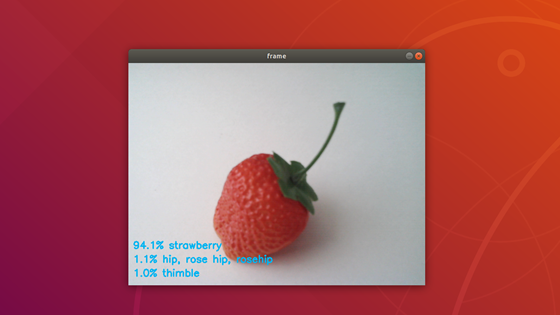
基本的に今までご紹介した技術の組合せや応用で出来ますのでソースコードをコピペする前に挑戦してみて下さい
- リアルタイムカメラ
- テキスト描画
- 文字列のスライス
etc
様々な記述方法があると思いますが、こちらに回答例を挙げておきます。
import cv2import numpy as np# モジュール読み込みfrom openvino.inference_engine import IENetwork, IEPlugin# ターゲットデバイスの指定plugin =# モデルの読み込みnet =exec_net = plugin# 入力データと出力データのキーを取得input_blob =out_blob =# ラベル読み込みlabels = np# カメラ準備cap = cv2camera_width =camera_height =# メインループwhile True:# キーが押されたら終了key = cv2if key != -1:break# カメラ画像読み込みret, frame = cap# 入力データフォーマットへ変換img = cv2 # HeightとWidth変更img = img # HWC > CHWimg = np # CHW > BCHW# 推論実行out = exec_net# 出力から必要なデータのみ取り出しout =# 不要な次元を削減out = np# 降順でベスト3のインデックスを抽出index_order = np# テキスト表示位置y座標初期値text_y = camera_height - 80# ベスト3のインデックスについてラベルと値を表示for index in index_order:# 左側の文字列10文字は取り除いてラベルを取得label =label =# outを百分率にして小数点2桁以下は丸めて、文字列化value = * 100value =value = + '% '# 文字の表示cv2# テキスト表示位置y座標増加text_y = text_y + 30# 画像表示cv2# 終了処理capcv2
実行時は、なるべく画像認識させたいものが一番大きく映るようにカメラを向けてください。
今までに出てきていない関数を使いましたので、3点ほど少し解説します。
1点目です。cap.getでカメラの幅と高さを取得することができます。今回使っているのはcamera_heightだけですが、ついでにcamera_widthも取得しています。
ウィンドウサイズの高さを知ることにより、putTextの表示位置を下側基準で指定することに使っています。
camera_width =camera_height =# ...text_y = camera_height - 80
2点目は、roundを使うと小数点以下の桁を指定して丸めることができます。第一引数に対象の変数、第二引数に丸めたい桁数を指定します。ちなみに「丸める」というのは、ほぼ四捨五入と近い意味ですが、厳密には異なりますので、気になる人は調べてみてください。
value =
3点目はstrと文字列連結です
Pythonでは+を使うことで簡単に文字列連結が出来ます。ただし、数値と文字列を連結したい場合は、事前に数値を文字列化する必要があり、str関数を使うことで可能です。
value = + '% '
以上、「Model Optimizer活用の画像分類」でした。