Inference Engineでランドマーク回帰
2020/05/26
「AI CORE XスターターキットとOpenVINO™ですぐに始めるディープラーニング推論」シリーズの6回目記事です。
このシリーズは、「ディープラーニングとは何か」から始まり、「各種ツールの使い方」「プログラミング基礎」「プログラミング応用・実践」までをステップバイステップでじっくり学び、自分で理解してオリジナルのAIアプリケーションが作れるようになることを目指しています。

第6回目はOpenVINO™のInference Engineを使ってディープラーニング推論を学びます。具体的には顔画像からランドマーク回帰、つまり目・鼻・口の位置推定を行います。
目次
- 必要なファイル準備
- ディープラーニング推論実行
- Inference Engine解説
- その他のコードと実行結果の解説
- 入力画像に出力結果を描画
必要なファイル準備
今回からいよいよPythonコードでディープラーニング推論を実行してゆきます。推論を行う際に必要なファイルはコード以外に2種類あります。1つは推論の対象とする「入力画像」、もう1つは「モデルと重み」です。
入力画像
入力画像は顔のみが映っている画像であれば何でもOKです。ここではこちらのページの画像を使ってみます。webサイト上でトリミングが可能です。ざっくり以下のような領域でトリミングしてダウンロードしてください。

ファイル名はphoto_face.jpgに変更します

imageというフォルダを新規作成して、photo_face.jpgをその中に移動しておいて下さい。
モデルと重み
第1回目の概要で説明したモデルと重みです
intelのOpen Model Zooという場所から探してダウンロードすることも可能ですが、OpenVINO自体には便利なツールが用意されているので、今回はツールを活用します。
端末を開いてdownloader.pyのあるディレクトリへ移動します。以下のコマンドを実行してください。
cd /opt/intel/openvino/deployment_tools/tools/model_downloader
続いてlandmarks-regression-retail-0009のダウンロードを実行します。以下のコマンドを実行してください。
python3 downloader.py --name landmarks-regression-retail-0009 --output_dir ~/workspace
workspaceの中にintelフォルダが作成され、その中にlandmarks-regression-retail-0009フォルダ、さらにその中に FP16, FP32, FP32-INT8 が作られ、それぞれの中に binと xmlの2つのファイルが格納されていると思います。
ディープラーニング推論実行
これで準備はできましたので、workspaceフォルダ直下で下記コードをコピペして作成し実行してみて下さい
# importimport cv2import numpy as npfrom openvino.inference_engine import IENetwork, IEPlugin# ターゲットデバイスの指定plugin =# モデルの読み込みnet =exec_net = plugin# 入出力データのキー取得input_blob =out_blob =# 画像読み込みframe = cv2# 入力データフォーマットへ変換img = cv2 # HeightとWidth変更img = img # HWC > CHWimg = np # CHW > BCHW# 推論実行out = exec_net# 出力から必要なデータのみ取り出しout =# 不要な次元を削減out = np# 中身を出力print(out)
このような結果が表示されたと思います。ただし、トリミングした領域は少し異なると思いますので、数値は各自で異なります。
※もしエラーが出た場合は、画像ファイル名やフォルダ名、画像ファイルの保存場所を確認してください
これがディープラーニングの推論です。制御文も繰り返し文もなく、とても短いシンプルなコードですよね! 結果もあっさりしています。
それでは、コードや結果の詳細について見てゆきましょう。
Inference Engine 解説
Inference Engineは推論エンジンのことで、プログラミングで呼び出して使います。
4つのステップで簡単に使うことができます
- モジュール読み込み
- ターゲットデバイスの指定
- モデルの読み込み
- 推論実行
Inference Engine Python APIの詳細はこちらにありますが、1つずつ解説してゆきます!
モジュール読み込み
Inference Engineの中のIENetworkとIEPluginというクラスを使うため、from ... import ... というimport形式を使って読み込んでいます。
from openvino.inference_engine import IENetwork, IEPlugin
ターゲットデバイスの指定
どのデバイスを使用してInference Engineを動かすかを指定します。
主にCPU, GPU, FPGA, MYRIADなどがありますが、今回はIntel® Movidius™ Myriad™ Xを使うため、MYRIADを引数に渡しています。deviceはキーワード引数です
plugin =
これでpluginが出来ました。
モデルの読み込み
実際にはモデルファイルと重みファイルの2つを読み込んでいますが、モデルと重みのことを合わせてモデルと省略して呼ぶ場合があります。
最初のIENetworkの引数は、ファイルパスが長いため難しく見えますが、よく見れば先程ダウンロードしたxmlファイルとbinファイルを示しているだけです。これをnetに代入しています。
次の行で先ほどのpluginのメンバ関数であるloadを使ってnet情報を読み込んでいます。
net =exec_net = plugin
なお、 FP16, FP32, FP32-INT8の3種類がダウンロードされていると思いますが、MYRIADを使う場合は、サポートされているのは FP16のみです。詳細はこちらのページを参照してください。
これでexec_netが出来ました
推論実行
exec_netのメンバ関数であるinferを使うだけでディープラーニング推論ができます。
引数が一見複雑ですが、1つずつ見てゆくと分かります。
キーワード引数inputsに{input_blob: img}という辞書型のデータを指定しています。input_blobがキーで、imgが値です。input_blobとimgがどこから出てきたのかはこの後説明します。
out = exec_net
これで推論結果がoutに入力されてディープラーニング推論完了です
その他のコードと実行結果の解説
ディープラーニングの推論自体は先程の4つのステップで非常に簡単に出来ることが分かったかと思います。一方で実際のデータを入力したり、推論結果を確認するには色々と処理すべき点があります。
- 入出力データのキー取得
- 入出力データのフォーマット確認
- 入力データを整える
- 出力データを取り出す
入出力データのキー取得
先程の推論実行時に出てきたinput_blobと、出力データを取り出す際に出てくるout_blobの説明です。
Inference Engineにて推論を行う際、入力のデータと出力のデータは辞書型である必要があります。辞書型ということは「キー」と「値」を持っています。入力データのキーをinput_blob、出力データのキーをout_blobという変数に割り当てています。それぞれのキーの取得方法は以下の通りです。
# 入出力データのキー取得input_blob =out_blob =
モデル読み込み後であれば、この2行で入力データのキーと出力のキーを取り出すことができます。なお、このコードはどのモデルにも汎用的に使えます。このコードの詳細については、少し長くなるのでここでは割愛しますが、興味のある方はこちらのイテレータ―を参照してください。
入出力データのフォーマット確認
モデルに対し、どのようなフォーマットの画像を入力し、どのような内容で出力が返ってくるのかは、モデル毎に全て異なります。今回のモデルについては、インテルのこちらのサイトに詳細が書かれています。Inputsの項目には以下のように書いてあります。
Inputs
Name: "data" , shape: [1x3x48x48] - An input image in the format [BxCxHxW], where:B - batch size
C - number of channels
H - image height
W - image width
The expected color order is BGR.
ここから分かる情報は以下の通りです
- 48x48のカラー画像
- フォーマットは BCHW という順番
- B は大きさ1の次元
次にOutputsの項目を見てみます
Outputs
The net outputs a blob with the shape: [1, 10], containing a row-vector of 10 floating point values for five landmarks coordinates in the form (x0, y0, x1, y1, ..., x5, y5). All the coordinates are normalized to be in range [0,1].
ざっくりまとめると
- 要素数が10個のリスト
- 値は小数で、5つのランドマーク座標が含まれる
- 具体的には(x0, y0), (x1, y1), (x2, y2), (x3, y3), (x4, y4)
- 座標は0.0~1.0の範囲に正規化されている
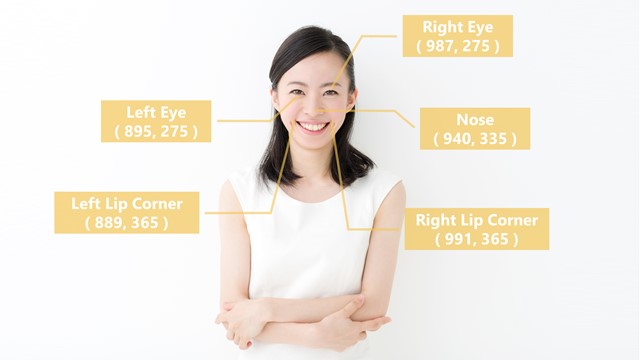
ランドマークは冒頭の概要にある通り、2つの目、鼻、2つの唇の位置のことです
The model predicts five facial landmarks: two eyes, nose, and two lip corners.
これでフォーマットが分かりましたので、この情報を元に入出力データを処理します
入力データを整える
OpenCVを使って、まず画像を読み込みます
frame = cv2
入力サイズは48x48なので、それに合わせてリサイズします
img = cv2 # HeightとWidth変更
フォーマットは BCHWの順なので、それに合わせます。元々の入力画像は HWC なので、まずその順番を CHW に入れ替えます
img = img # HWC > CHW
expand_dimsを使って B(大きさ1の次元)を加えます。
img = np # CHW > BCHW
これで画像データimgは要求されたフォーマットになりました
出力データを取り出す
推論後の結果はoutに入っていますが、辞書型になっています。キーであるout_blobを使うことで中身の値を取り出すことができます
out =
試しにこのコードの直後にprint(out)を加えて実行してみて下さい。以下のように余分な括弧が付いて出力されたかと思います。
ほとんどの括弧は大きさが1である次元を示している邪魔なものなので、squeezeを使って次元を削除します。
out = np
これでprintすると先程の出力結果になります
この値は以下の表のような内容を意味しています。
| Landmarks | x座標 | y座標 |
|---|---|---|
| 左目 | 0.29711914 | 0.17468262 |
| 右目 | 0.68408203 | 0.18615723 |
| 鼻 | 0.47851562 | 0.43237305 |
| 左唇 | 0.34448242 | 0.66308594 |
| 右唇 | 0.62158203 | 0.69091797 |
値は正規化されているため、入力画像のx座標の最小~最大を0.0~1.0、y座標の最小~最大を0.0~1.0としたときの座標値です。
入力画像に出力結果を描画
数値だけだと本当合っているのか分かりにくいので、実際に入力画像の上に出力結果を反映させます。具体的には出力結果の座標値に黄色の丸を描くとします。
次のコードをコピペして実行してみて下さい。
# importimport cv2import numpy as npfrom openvino.inference_engine import IENetwork, IEPlugin# ターゲットデバイスの指定plugin =# モデルの読み込みnet =exec_net = plugin# 入出力データのキー取得input_blob =out_blob =# 画像読み込みframe = cv2# 入力データフォーマットへ変換img = cv2 # HeightとWidth変更img = img # HWC > CHWimg = np # CHW > BCHW# 推論実行out = exec_net# 出力から必要なデータのみ取り出しout =# 不要な次元を削減out = np# 中身を出力print(out)# Landmarks検出位置にcircle表示for i in :x =y =cv2# 画像表示cv2# キーが入力されるまで待つcv2# 終了処理cv2
次のような画像が出力されます。
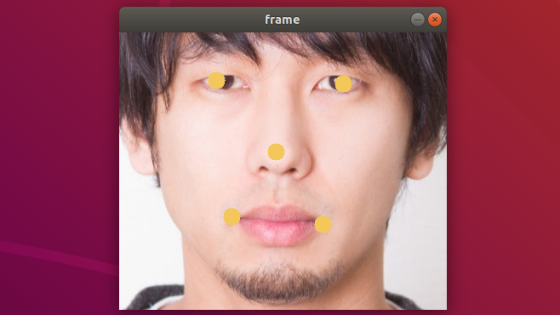
目・鼻・唇の位置とおおよそ合っているかと思います。
最初のコードからの追加点は以下の部分のみです。
# Landmarks検出位置にcircle表示for i in :x =y =cv2# 画像表示cv2# キーが入力されるまで待つcv2# 終了処理cv2
for文の説明です。
全体としては、outの要素からx座標とy座標をセットで2個ずつ取り出し、5つの円を描くという内容になっています。range(0, 10, 2)という書き方で、0, 2, 4, 6, 8 という要素の構成が得られます。out[i]にはx座標、out[i+1]にはy座標が取り出されますが、0.0~1.0に正規化されているため、元の画像サイズの領域に変換する必要があります。frame.shape[1]で元画像widthのサイズ、frame.shape[0]でheightのサイズが得られますので、それぞを掛け合わせています。cv2.circleは整数値で座標を指定する必要があるため、intを使って整数化しています。このようにして得られた x, yの位置にcv2.circleを使って黄色の塗りつぶし円を描いています。
その他は、OpenCV基礎で学んだ内容と全く同じです。
ぜひ、他の顔画像や、例えば上半身など顔以外の部分を含めるとどうなるかなど色々な入力画像で試してみて下さい。次回はディープラーニングで自動的に顔領域の検出を行いたいと思います。
以上、「Inference Engineでランドマーク回帰」でした。