ディープラーニング概要
2020/05/12

「AI CORE XスターターキットとOpenVINO™ですぐに始めるディープラーニング推論」シリーズの1回目記事です。
このシリーズは、「ディープラーニングとは何か」から始まり、「各種ツールの使い方」「プログラミング基礎」「プログラミング応用・実践」までをステップバイステップでじっくり学び、自分で理解してオリジナルのAIアプリケーションが作れるようになることを目指しています。

第1回目はディープラーニングやOpenVINO™ツールキットの概要について学びます。なお、本シリーズのコンテンツは全て無償で公開されます。
目次
- 最終的に何が学べるのか?
- 必要なスキルと開発の様子
- ディープラーニングの種類
- 画像認識の種類
- 学習と推論
- AIの正体
- OpenVINO™ツールキットとは
- OpenVINO™ツールキットで出来ること
- OpenVINO™ツールキットの対応環境
- OpenVINO™における推論手法
最終的に何が学べるのか?
このシリーズを最後まで学習すると、ディープラーニングを用いたオリジナルのアプリケーションが作れるようになります。
ポイントは3つです。
- どんな画像をディープラーニングに入力すれば良いのか?(ルールを知る)
- ディープラーニングから出力された数値は何なのか?(数値の意味を理解する)
- ディープラーニングからの出力結果をどう扱えばよいのか?(見える化を行う)
本シリーズでは、顔と目の位置検出を使ったアプリ作成を通して、このポイントを掴みます。これらをパターンとして掴むことにより、他のディープラーニングでも応用することができるようになります。
顔と目の位置検出
具体例として、メガネや帽子などをバーチャルに試着できるアプリを作ります。
スマホやWebアプリで似たようなものがありますが、そのようなアプリやライブラリを実行するのではなく、自分でアプリを作成します。また、OpenVINO™ツールキットであれば、インターネットを使わずローカルな環境で実行できるため、自分の顔などを安心してカメラで認識させることが出来ます。

静止画だけでなくwebカメラを使って、リアルタイム映像で試着可能です。
技術的にはディープラーニングを使って、顔を検出し、検出した顔領域から左右の目の位置を推定し、その情報を使ってメガネ画像等を描画します。なお、通常ディープラーニングは顔にメガネや帽子を描くことまでは行いません。ディープラーニングから得られるのは目の位置座標のみです。つまり、単にディープラーニングを実行するだけではなく、ディープラーニングから得られた結果をどう使いこなすのかについても学ぶことができます。
また、バーチャル試着で扱うのは顔や目だけですが、他にも表情や目線、頭の向き、関節の動き、年齢や性別、ジェスチャー、同一人物特定、歩行者、文字列など様々な情報をディープラーニングで取得可能で、応用の可能性は無限大にあります。
モデル変換と画像分類
その他、TensorflowやCaffeなど有名なフレームワークで学習されたモデルをOpenVINO™ツールキットで使えるように変換し、ディープラーニング画像分類も行います。

こちらもリアルタイムに認識可能です。
なお、ディープラーニング実行結果からstrawberryという文字列が出力される訳ではなく、実際にはたくさんの数値が出力されます。ディープラーニングは一言でいうと「計算」です。AIが人間のように考えて答えを出すわけではありません。「ディープラーニングとは計算」「出力結果が数値」とはどういうことなのか? なぜそれで画像認識できるのか?、本シリーズを通して実際にプログラミングを行うことにより、この辺の感覚も理解できるようになります。
必要なスキルと開発の様子
本シリーズではディープラーニング推論のプログラミングを行います。最低限、PCの一般的な操作やキーボードでタイピング出来ることが必須となります。これまでに何らかのプログラミング言語を使って初級レベルでコードを作成した経験があることが望ましいですが、初心者の方向けにも丁寧に説明しますので、安心してください。その他、数学的な知識や、データサイエンス・機械学習の知識、UbuntuやLinuxの使い方などを知らなくても全く問題ありません。
プログラミング開発の様子がどんな感じなのかを動画でお見せします。
猫画像に文字列を描画するというコード例です。コードやコマンドの入力は少し速度を早めて再生しています。
非常に短いコードでかつ簡単に実行や修正ができるのが分かったかと思います。
動画の中では以下の内容を行いました。
- 画像ファイルの表示確認
- コード入力
- コード実行
- コード修正
- コード再実行
Pythonを用いていますので、コンパイルやビルド等は不要で、いきなり実行できます。実行するのに少しコマンドを使っていますが、2~3個程度のコマンドを覚えておけば問題ないですし、コマンド打ち込みは過去打ち込んだ履歴をショートカットキーで呼び出せるため、効率よく実行できます。
この動画ではディープラーニングはまだ使っていませんが、少しコードが増える程度でやり方は同じです。また、入力が静止画像でしたが、USBカメラによるリアルタイム入力もコードを少し修正すれば同じやり方で出来ます。
どうでしょう? 驚くほど、簡単かつスムーズに開発できる気がしませんか?
ディープラーニングの種類
ディープラーニングの種類として主に以下4つを説明します。
- 画像認識
- 自然言語処理
- 画像生成
- 強化学習
画像認識

ディープラーニングが最も実用化されているのが画像認識の分野です。
画像認識はコンピュータビジョン、つまりロボットの目とも呼ばれていて、既に人間の目の精度を超えています。工場の目視検査や医療の画像診断、小売り業での自動精算や自動運転車のカメラなど、様々な分野に搭載されています。
画像認識で使われている技術(ネットワークやモデルと呼ばれている)はCNN(Convolutional Neural Network)と呼ばれるものです。簡単に喩えるなら、画像のピクセル1点1点のみで処理しているのではなく、画像としての特徴を掴んで処理していると言えます。
今回のシリーズではこのCNNを使ったディープラーニングを取り扱います。
自然言語処理

ディープラーニングによる自然言語処理は、翻訳や音声認識などに実用的に活用されています。
自然言語処理に使われている代表的なモデルはRNN(Recurrent Neural Network)というものです。2016年頃にGoogole翻訳がこの技術に切り替えてから、飛躍的に精度が向上しました。
また、RNNの進化版としてLSTM(Long Short-Term Memory)というモデルも有名です。RNNやLSTMは他にも株価予測や売上予測など時系列データの予測にも使われています。
さらに近年ではより精度の高いBERTと呼ばれるモデルが、自然言語処理で幅広く使われるようになっています。
画像生成

複数の画像で得た特徴を使って、新たな画像を生成する技術です。
GAN(Generative Adversarial Network)やVAE(Variational AutoEncoder)などのモデルが有名です。
例えば、猫の画像をゴッホ風にしたり、実在する複数のアイドル写真から架空のアイドル画像を生成したり、テキストから画像生成を行うなどが可能です。
既に、本物の写真か生成された画像なのかの見分けがつかなくなるくらいに精度が高くなっており、今までになかった新たなサービスや実用化がこれから続々と生まれると期待されています。
強化学習

強化学習とは簡単にいうと、赤ちゃんが成長するように学習する技術です。赤ちゃんは限られた環境の中で様々な動きにチャレンジして成功と失敗を繰り返して、だんだんと学習してゆきます。
ディープラーニングを使った強化学習の有名なモデルとしてDQN(Deep Q-Network)があります。代表例はGoogleが開発し、世界ランク一位のプロ囲碁棋士を破ったAlphaGo(アルファ碁)です。ロボットやクルマの自動制御にも適しており、産業での実用化はこれから始まってゆくと予想されます。
画像認識の種類
先程の画像認識の説明で出てきたCNNですが、その中にもいくつか種類を分けることができます。
- 分類
- 回帰
- 物体検出
分類(Classification)

分類とは簡単にいうと「何なのか」を示すものです。
予め、いくつかのクラス(画像の種類)が用意されており、入力画像がどのクラスに分類されるのかを推定します。上記のイメージは猫クラスである確率が高いという結果を示しています。
回帰(Regression)

回帰とは簡単にいうと「どのくらいなのか」を示すものです。
この場合はクラスで分けるのではなく、連続的な数値で結果を表します。上記のイメージは年齢が約22歳であるという結果を示しています。
物体検出(Object detection)

検出とは簡単にいうと「何がどこにあるのか」を示すものです。
「分類」と「回帰」を組み合わせた感じです。上記のイメージは、顔分類と位置回帰の結果から、顔がどこにあるのかを示しています。上記の画像では顔を推定した位置にバウンディングボックスと呼ばれる四角形を描いています。
検出がさらに進化した「セグメンテーション(Segmentation)」という技術もあります。ピクセル単位で何がどこにあるのかを示すことができるため、画像だけで「何が起きているのか」まで推測することが可能になります。
学習と推論
ディープラーニングは主に3つのフェーズ(段階)に分けることが出来ます。
- 学習データ作成
- 学習
- 推論
今回は回帰を使って年齢を推定するAIを例に取って説明します。
学習データ作成
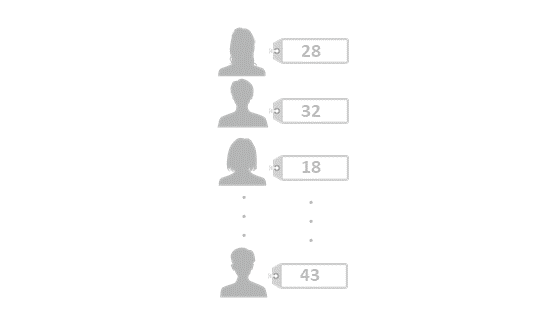
まず、学習するための顔画像をたくさん用意します。数に決まりはありませんが、数千~数万データくらいをとりあえずイメージしてください。またその顔に対する正しい年齢をデータにタグ付けします。この作業はアノテーションとも呼ばれています。
学習
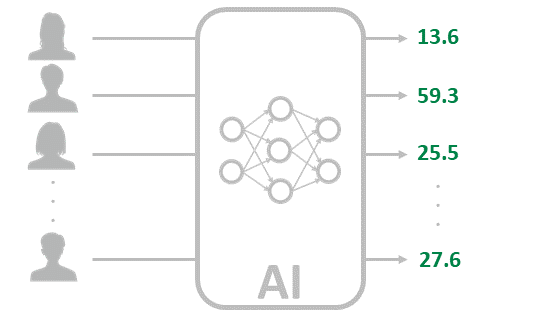
実はAIというのは最初からあります。テンプレートみたいなものがあって、適当に選択するとイメージしてください。ただし、AIの中身であるパラメーターはランダムの状態です。
冒頭で少し、ディープラーニングは計算であると述べました。つまり、このAIに何らかの画像を入れると、とりあえず計算して出力を出します。単なる計算式なので、どんな画像を入力しても必ず出力が出てきます。ただし、中身のパラメーターがランダムであるため、ランダムな答えが出力されます。
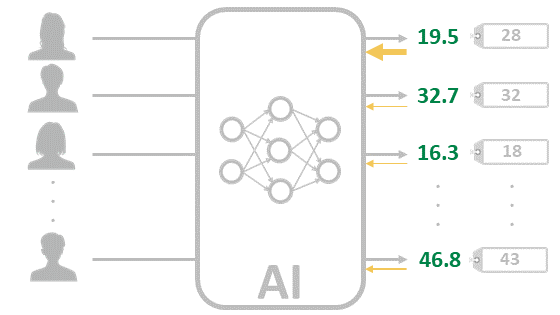
とりあえず置いたAIに先ほどの学習データを入力した様子です。出力は当然ランダムな値になります。
この出力とタグ付けした値を比較し、その差分をAIにフィードバックします。このとき、差分が大きい程、フィードバックされる量が大きいとイメージしてください。画像の黄色い矢印がフィードバックをイメージしています
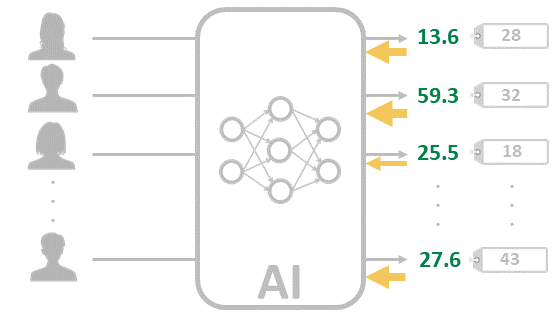
フィードバックされたことによりAIは以前よりも精度が向上します。再びこの少し精度が上がったAIに学習データを入力します。最初に比べて、結果がタグの値に近づきました。
なお、ディープラーニング学習は画像データを記憶して、入力画像と比較しているわけではありません。繰り返しますが、行っているのは計算です。また、各画像毎に個別の計算式があるわけではなく、計算式は1つです。学習するすべての画像について、タグ付けされた値になるべく近づくように膨大なパラメーターを調整して1つの計算式を作っています。
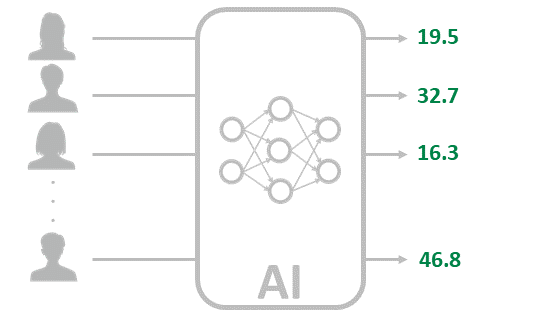
再び差分をAIにフィードバックします。またAIの精度が上がり、またデータを入力して、フィードバックして・・・とずっと繰り返して、精度が飽和してきた時点で終了となります。実際には大量のデータを使って何度も実行とフィードバックを行います。これが、ディープラーニングの学習です。
推論
学習フェーズで出来たAIに対し、これまで学習したことのないデータを入れてみて予測させるのが、推論フェーズです。学習の精度が良く、適切な入力データである程、良い結果が出てきます。
例えば、学習データに使った画像が全て日本人で、推論する画像は欧米人という場合は良い結果が出ない場合があります。
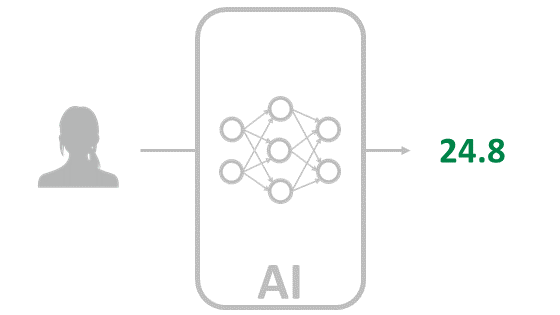
推論フェーズは、学習フェーズと違って、データは1つですし、フィードバックすることもありません。
AIの正体
AIの中身は2つのファイルで構成されています。
今回使用するOpenVINO™ツールキットの場合はxmlファイルとbinファイルです
学習時の最初に適当にテンプレートを選んだと思いますが、それがいわゆる「モデル」と呼ばれるものでxmlファイルの中に入っています。学習を繰り返すことによりパラーメータの値を更新しましたが、このパラメーターが「重み」と呼ばれるものでbinファイルの中に入っています。
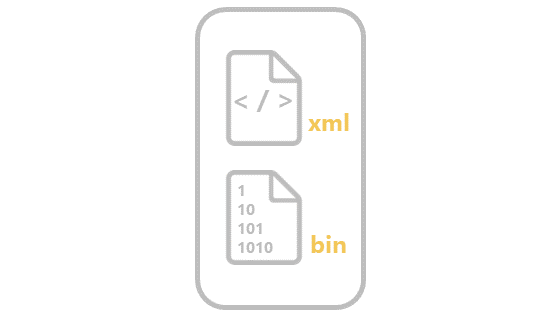
このたったの2つのファイルがAIの正体の全てです。
ディープラーニングは「人間の脳の神経細胞(ニューロン)の仕組みを模した構造」などと説明されますが、難しく考える必要はありません。計算の処理の仕方が脳の伝達っぽいというだけで、実際には膨大で面倒な計算をひたすら行っているだけです。計算を行うのはコンピューターなので、この2つのファイルの扱い方が分かれば、ディープラーニングを使いこなすことが可能となります。
OpenVINO™ツールキットとは

今回活用するOpenVINO™ツールキットについて、簡単にまとめます
詳細はこちらの公式ページに書いてありますので、ここでは代表的なもののみにポイントを絞って説明します。
ディープラーニング推論のためのツール
キットという言葉の通り、OpenVINO™ツールキットにはツールやライブラリ、サンプルなど色々な道具としてのソフトウェアが入っています。
以下に代表的なものを挙げました
- Inference Engine
- Model Optimizer
- OpenCV
- Open Model Zoo
Inference Engineは、推論エンジンのことで、プログラミングの中で呼び出して使います。
Model Optimizerはモデル変換ツールです。後ほど説明します。
OpenCVはコンピュータビジョンライブラリです。OpenCVは静止画像やカメラ映像の入出力、文字や図形描画、ちょっとした画像処理などに使います。
Open Model Zooには学習済モデルや、サンプルアプリ、サンプルソースコードなどがあります。非常にたくさんのサンプル数です。
無償で使えるソフトウェア
OpenVINO™ツールキットは無料でダウンロードとインストールができるだけでなく、全機能を制限なく使うことができます。期間限定、有料版、広告表示などもありません。商用利用も含めて無償です。2018年9月に初めてリリースされ、何度かバージョンアップされており、ソフトウェアとして安定しています。
エッジコンピューティング用途
ディープラーニングの実行環境として「クラウドコンピューティング」と「エッジコンピューティング」の2つに大きく分かれます。
「クラウドコンピューティング」はクラウド側でディープラーニングを実行することを指します。ある程度までは無料で使える場合がありますが、期間やデータ上限などを超えると有料になるケースがほとんどです。また、カメラで撮った写真をアップロードして推論することは出来ますが、普通の通信でカメラ映像をリアルタイムに推論することは困難です。5G通信を使えば可能かもしませんが、通信料金の発生や場所の制限等があります。
一方の「エッジコンピューティング」は、通信を使うことなく任意の場所でデバイス側のみで完全に閉じて処理を行うことが出来、以下のメリットがあります。
- リアルタイム応答
- 通信料ゼロ
- セキュリティ低リスク
OpenVINO™ツールキットはクラウドを使用しない「エッジコンピューティング」です。カメラ映像をリアルタイムに推論することも可能ですし、データをネット上にアップしないので、通信料ゼロでセキュリティ的にも安心感があります。
OpenVINO™ツールキットで出来ること
ディープラーニング推論
OpenVINO™ツールキットでは「ディープラーニング推論」を取り扱います。
言い換えると「ディープラーニング学習」は出来ないということです。
学習させるにはディープラーニング用の「フレームワーク」を使って行う必要がありますが、学習は必須ではありません。実は、ディープラーニングに関わる技術は様々なものが無料で公開されています。フレームワークもそうですが、画像を処理するためのライブラリ、学習するための大量データ、モデル、そして「学習済みモデル」もたくさん公開されています。本シリーズでは豊富にある「学習済みモデル」を活用します。
ディープラーニングには前述のように「CNN」「RNN」「GAN」「DQN」などがあります。OpenVINO™ツールキットで主に対応しているのは「CNN」です。
「モデル」は様々な「レイヤー」というもので構成されており、OpenVINO™ツールキットのバージョンアップと共に対応レイヤーが増えています。またプロセッサによっても対応レイヤーが異なりますのでご注意ください。詳細は公式ウェブサイトをご参照願います。
学習済みモデルの変換
OpenVINO™で推論実行可能な「学習済みモデル」はIR(Intermediate Representation)という形式のみです。IRは2つのファイルで、それぞれ xmlとbinの拡張子です。
他の学習済みモデルの形式の場合は、OpenVINO™ツールキットに入っているModel Optimizerを使ってIRに変換します。
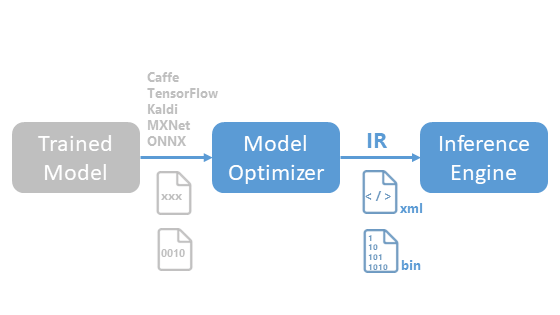
Model Optimizerが対応している「学習済みモデル」の形式は以下の通りです。
- Caffe
- TensorFlow
- Kaldi
- MXNet
- ONNX
上記にありませんが、良く使われるKerasはTensorFlow形式に一旦変換することで、Model Optimizerで取り扱うことが出来るようになります。また、フレームワークはPyTorch, NNC(Neural Network Console)など、他にも多数ありますが、ディープラーニングの共通フォーマットである「ONNX」形式で出力することにより、OpenVINO™ツールキットで扱うことが可能です。
OpenVINO™ツールキットの対応環境
OpenVINO™ツールキットの開発にはPCが必要です。
ただし、デスクトップPCだけではなく、ノートPCや超小型PC、コンピュータボードなどでも対応可能です。PCとしての形態よりも、その中身のOSやプロセッサが重要となります。
OS
対応OSです。
- Linux
- Windows10
- MacOS
詳細な対応OSバージョンは公式サイトをご参照ください
プロセッサ
プロセッサとは主に以下のようなものを指します。
- CPU
- GPU
- FPGA
- VPU
CPU, GPU, FPGAは一般的な名称なので説明は割愛しますが、VPUだけ軽く説明すると、"Vision Processing Unit"の略で、画像認識などのコンピュータービジョンの処理に特化したプロセッサーです。次回紹介する「AI CORE Xスターターキット」や「Neural Compute Stick」などに搭載されている「Myriad™」が該当します。
OpenVINO™ツールキットは様々なプロセッサに対応していますが、インテル製の比較的新しいものに限られますので注意して下さい。インテルCPUには Xeon, Core, Pentium, Celeron, Atomなどがあります。
ちなみに、公式サイトには、CeleronやAtomの記述がないですが、LinuxOSでApollo Lake世代以降であれば動作できるようです。
開発プログラミング言語
OpenVINO™ツールキットでプログラミングを行う手法として主に3つあります
- C++
- Python
- OpenCV DNN
推論はOpenVINO™ツールキットのInference Engineを呼び出して使いますが、1と2はそのまま呼び出す方法で、3はOpenCVを経由して呼び出す方法です。1と2はOpenCVを使わないわけではなく、Inference Engine呼び出しとは別用途でOpenCVを活用します。
本シリーズでは2のPythonで進めてゆきます。
OpenVINO™における推論手法
OpenVINO™ツールキットでディープラーニング推論を行う方法として3つあります
| モデル | 他ツールで学習 | Model Optimizer | Inference Engine |
|---|---|---|---|
| 1. Pre-Trained | - | - | ✔ |
| 2. Public | - | ✔ | ✔ |
| 3. Original | ✔ | ✔ | ✔ |
1のPre-Trained Modelは、インテル学習済みモデルのことで、プログラミング上でInference Engineを使うだけで推論が可能です。Pre-Trained Modelには、人の姿、顔のパーツ、クルマ、バイク、歩行者などを対象とした、実用的な学習済みモデルがたくさん用意されています。ジャンルとしては、Retail系(小売りや屋内向け)、Adas系(自動運転向け)、Barrier系(セキュリティカメラ向け)などがあります。詳細はこちらを参照してください。

2のPublic Modelは、一般的に公開されている学習済みモデルのことです。例えば、GoogLeNet、SqueezeNet、SSDやYoloなどです。Inference Engineで扱えるようにするために、プログラミング前にModel Optimizerを使ってモデルの変換が必要となります。
3のOriginal Modelとは、例えば自分で飼っている猫を学習して他の猫と判別したいなど、オリジナルの学習データを使ってディープラーニングしたい場合です。学習データを集め、TensorflowやCaffeなどのフレームワークを使って事前に学習した後に、Model Optimizerで変換することで、Inference Engineで推論可能となります。
次回は、本サイトで進める具体的な開発環境を説明します。
以上、「ディープラーニング概要」でした。