2019/07/22
NumPyプログラミングを学ぶ

どうも、ディープなクラゲです。
「OpenVINO™ でゼロから学ぶディープラーニング推論」シリーズの6回目記事です。
このシリーズは、ディープラーニング概要、OpenVINO™ツールキット、Neural Compute Stick、RaspberryPiの使い方、Pythonプログラミングをゼロから徹底的に学び、成果としてディープラーニング推論アプリケーションが理解して作れるようになることを目指します。

第6回目はNumPyを学びます。
「OpenVINO™ でゼロから学ぶディープラーニング推論」で使うNumPyに絞ってじっくりと説明してゆきます!
前半は配列としての基礎、後半は画像データとの関連について学びます。
【 目次 】
- NumPyとは
- ndarray
- 初期化
- 要素参照
- 最大値のインデックス
- 形状
- ndarrayと画像データ
- スライス
- 次元
NumPyとは
NumPyとは数値計算を効率的に行うための拡張モジュールです。簡単に言うと、ベクトルや行列などの多次元配列を高速に計算するためのライブラリです。また画像データとも密接な関係があります。
OpenCVと同様に、NumPyを使用するためにはnumpyモジュールをimportする必要があります。
import numpy
上記のimportでも全く問題ないのですが、慣例的に np という別名を付けることが一般的です。
import numpy as np
ndarray
NumPyで扱う多次元配列は ndarray という名称です。(N-dimensional array の略)
ndarrayはPython基礎で習ったリストと関連性があります。リストと表記が似ていて混同しやすいので注意しましょう。
ちなみに、プログラムのソースコードには ndarray という関数は出てきません。
import numpy as npa =b = npprint(b)# 実行結果# [10 20 30]
上記のソースコードの解説です。
変数 a はPython基礎で習ったリストです。
変数 b がndarrayです。 np.arrayという関数を使ってリストをndarrayに変換しています。
最後にprintで表示していますが、ndarrayはリストと異なり、カンマが無いのが特徴です。
初期化
ndarrayの初期化方法です。既に先ほどのコードで出ていますが、np.arrayを使って行います。
ここでは、具体的にリストとndarrayの違いを比較しながら確認してゆきましょう。
実行結果を見ると分かりますが、リストにはカンマがついていますが、ndarrayにはカンマが無いのが確認できます。
import numpy as np#リストa =print(a)#ndarrayb = npprint(b)# 実行結果# [10, 20, 30]# [10 20 30]
2次元の場合の比較です
ndarrayの結果は途中で改行が入っています。
import numpy as np#リストa =print(a)#ndarrayb = npprint(b)# 実行結果# [[10, 20, 30], [40, 50, 60]]# [[10 20 30]# [40 50 60]]
要素参照
要素参照についても、具体的にリストとndarrayの違いを比較しながら確認してゆきましょう。
1次元の場合の要素参照はリストもndarrayも同じです。
import numpy as np#リストa =print()#ndarrayb = npprint()# 表示結果# 20# 20
2次元の場合、表示結果は同じですが、参照方法が異なることに注目してください。
実はndarrayも b[1][2] という書き方でもOKなのですが、ndarrayの場合は慣例的に b[1, 2] という書き方をします。
import numpy as np#リストa =print()#ndarrayb = npprint()# 表示結果# 60# 60
最大値のインデックス
np.argmax は 配列(リストやndarray)の中で最大値の要素のインデックスを値で返します。
import numpy as npa = npb = npprint(b)# 表示結果# 1
配列の中の最大値は 50 ですが、そのインデックス 1 であるため、このような実行結果になります。最大値そのものではなく、最大値があるインデックスを返すというのがポイントです。
形状
ndarrayは「次元」以外の要素として「形状」があります。形状は各次元における要素の数のことです。shapeを使うと、形状を表示させることができます。
まずは1次元の例です。
実行してみると、中途半端なカンマで終わっていますが、要素数が 4 ということで合っていると思います。1次元の場合はこのような (x,) という中途半端なカンマで表示されます。
import numpy as npa = npprint(a.shape)# 表示結果# (4,)
今度は2次元の例です。実行してみると(3, 4) ということで一致しています。
import numpy as npa = npprint(a.shape)# 表示結果# (3, 4)
次に3次元の例。長いので途中で改行しました。結果は (2, 3, 4 ) で一致しています。
import numpy as npa = npprint(a.shape)# 表示結果# (2, 3, 4)
ndarrayと画像データ
冒頭で述べたようにndarrayと画像データは密接な関係があります。これまで使ってきた変数と画像の型を比較したいと思います。type関数を使うと、変数の型を見ることができます。
import numpy as npa = 100b = 3.14c = 'jellyfish'd =e = npprint()print()print()print()print()# 表示結果# <class 'int'># <class 'float'># <class 'str'># <class 'list'># <class 'numpy.ndarray'>
整数、小数、文字列、リスト、ndarrayと表示されていると思います。
次にOpenCVで使った cat.png を cv2.imread して型と形状を見てみましょう
import cv2image_file = 'cat.png'img = cv2print()print(img.shape)# 表示結果# <class 'numpy.ndarray'># (600, 800, 3)
実は cv.imread で読み込まれた画像はndarrayに変換されていました。
そして形状をみると (600, 800, 3) であり、(高さ, 幅, カラーチャンネル)を示しています。カラーチャンネルは 青と緑と赤の3色です。
個別に画像の幅を取得したい場合は形状の0番目の要素、高さを取得したい場合は形状の1番目の要素を指定すれば得られます。
import cv2image_file = 'cat.png'img = cv2print(img.shape)print(img.shape)# 表示結果# 600# 800
スライス
ndarrayにて [n:m]を使うとndarrayから条件にあった要素全てを取り出すことができます
取り出される要素は n ~ m-1 番目です。 m-1 というのがちょっとややこしいですね。
実際のプログラムで確かめてみましょう。
import numpy as npa = npprint()# 表示結果# [30 40 50 60 70]
先程のコードは1次元のスライスでしたが、2次元や3次元でも同様に使うことができます。
スライスを画像データに適応すると、画像の1部分だけの取得が可能になります。
import cv2image_file = 'cat.png'img = cv2cv2cv2cv2
猫の顔の部分だけが表示されたと思います。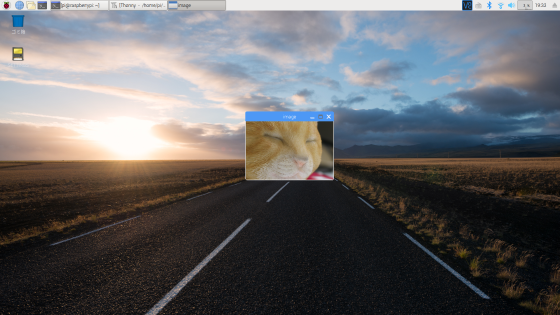
ndarrayの順番は [高さ方向, 幅方向] であることに注意してください。
次元
これまでも、1次元、2次元、3次元と次元を扱ってきましたが、ここでは次元を参照・変更するという関数について説明します。
次元数の参照:ndim
ndimはndarrayの次元数を参照することができます。
import numpy as npa = npprint(a.ndim)b = npprint(b.ndim)c = npprint(c.ndim)# 表示結果# 1# 2# 3
次元の入れ替え:transpose
transposeは引数で指定した順番通りに軸を入れ替える関数です
実際のコードで見た方が理解しやすいです
import numpy as npa = npprint(a)print('----------')b = aprint(b)# 表示結果# [[ 1 2 3 4]# [ 5 6 7 8]# [ 9 10 11 12]]# ----------# [[ 1 5 9]# [ 2 6 10]# [ 3 7 11]# [ 4 8 12]]
print('----------')は表示結果を見やすくするために入れています。a.transpose(0, 1)と書いた場合は変化はありません。2次元の場合はa.transpose(1, 0)と書くことで軸が入れ替わります。
3次元である画像にtransposeを適用した例を見てみましょう
import cv2image_file = 'cat.png'img = cv2cv2cv2cv2
これは分かりやすい結果だと思います。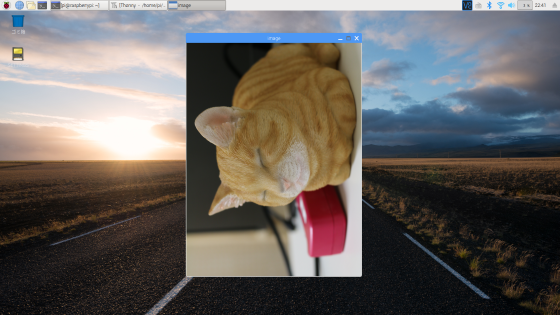
画像データは(高さ, 幅, カラーチャンネル)という並びであることを先ほど言いましたが、これを英語で書くと(Hight, Width, Channel)になります。この頭文字を取ってHWCと略します。
上記のコードではHWCからWHCへの変換したデータを表示しているということです。
HCW,WCH,CHW,CWHへの変換自体は可能です。ただし、それらのデータで表示を行うとエラーになりますので気を付けて下さい。
次回取り扱う推論エンジンの画像フォーマットはCHWです。そのためこのようなコードが必要になります
img = img # HWC > CHW
次元の削減:squeeze
squeezeは大きさが1である次元を削除する関数です。これも実例をみて確かめてみましょう
まずは、大きさが1である次元の例を書いてみます。
import numpy as npa = npprint(a)print(a.ndim)print(a.shape)print('----------')b = npprint(b)print(b.ndim)print(b.shape)print('----------')c = npprint(c)print(c.ndim)print(c.shape)# 表示結果# [1 2 3 4]# 1# (4,)# ----------# [[1 2 3 4]]# 2# (1, 4)# ----------# [[[1 2 3 4]]]# 3# (1, 1, 4)
変数aは1次元、bは2次元、cは3次元のndarrayですaは今まで通りのndarrayですが、bやcは余分に[ ]が付いているのが分かるかと思います。
これが大きさが1である次元を含んでいる状態です。
squeezeは簡単に言うと、この余分な[]を取り除き、次元を減らす関数です。
以下のコードでは先の全てのndarrayに対して、squeezeを加えてみた例です。
import numpy as npa = npa = npprint(a)print(a.ndim)print(a.shape)print('----------')b = npb = npprint(b)print(b.ndim)print(b.shape)print('----------')c = npc = npprint(c)print(c.ndim)print(c.shape)# 表示結果# [1 2 3 4]# 1# (4,)# ----------# [1 2 3 4]# 1# (4,)# ----------# [1 2 3 4]# 1# (4,)
aは元々、大きさ1の次元はないため変化ありませんが、bとcは余分な[]が消えているのが分かるかと思います。
次元の追加:expand_dims
expand_dimsは逆に大きさ1の次元を追加することができます。
キーワード引数としてaxis=0を書くことにより次元の追加先を0番目の軸(一番外側の次元)に指定することができます。
import numpy as npa = npa = npprint(a)print(a.ndim)print(a.shape)print('----------')b = npb = npprint(b)print(b.ndim)print(b.shape)print('----------')c = npc = npprint(c)print(c.ndim)print(c.shape)# 表示結果# [[1 2 3 4]]# 2# (1, 4)# ----------# [[[1 2 3 4]]]# 3# (1, 1, 4)# ----------# [[[[1 2 3 4]]]]# 4# (1, 1, 1, 4)
大きさ1の次元が追加されているのが分かるかと思います。
このようにいくらでも次元を増やすことができます。一見意味無いように思えますが、次元数のフォーマットを合わせる際に使う場合があります。
以上、「NumPyプログラミングを学ぶ」でした。