2018/12/07
【12.実践5】GenderNetで性別リアルタイム推定&画像出力

どうも、ディープなクラゲです。
「ゼロから学ぶディープラーニング推論」シリーズの12回目記事です。
このシリーズでは、Neural Compute StickとRaspberryPiの使い方をゼロから徹底的に学び、成果としてディープラーニングの推論アプリケーションが作れるようになることを目指しています。

第12回目は、カメラ映像からリアルタイムに画像認識させ、性別を判定し、性別に応じた画像をフルスクリーン表示させます
検証しやすいようにフルスクリーンにカメラ映像を表示したり、精度を上げるために推論前に顔認識による前処理なども行っています。
分かりやすいように、クラゲが段階的に解説してゆきます!
【 目次 】
- ソースコード入手
- アプリ実行
- demo1
- demo2
- demo3
- ソースコード解説
- demo1
- demo2
- demo3
ソースコード入手
実行するためのソースコードをダウンロードします。
Pythonソースコードはdemo1.py, demo2.py, demo3.pyの3つです。それぞれ独立に実行するソースコードで、段階的に内容が追加されています。先程の動画で実行しているプログラムは最後のdemo3.pyです。
それに加えて、画像ファイルcake1366.jpgとcar1366.jpgの2つ、顔検出用に使う分類器haarcascade_frontalface_default.xmlの1つも使用します。
つまり、ダウンロードすべきファイルは6ファイルです
ターミナルにて、適当な場所に移動します
cd /home/pi/ダウンロード
以前にダウンロードしたフォルダ "movidius-ncs" がある場合は一旦削除して下さい(前回ダウンロードしたのがつい最近であればそのまま使えます)
git cloneコマンドを使ってダウンロードします
git clone https://github.com/electricbaka/movidius-ncs.git
movidius-ncsというフォルダが出来ていると思います。
ファイルマネージャーを2つ開きます
- /home/pi/ダウンロード/movidius-ncs/GenderNet
- /home/pi/workspace/ncappzoo/caffe/GenderNet
以下の6つのファイルを "/home/pi/workspace/ncappzoo/caffe/GenderNet" へコピーすればOKです
- cake1366.jpg
- car1366.jpg
- demo1.py
- demo2.py
- demo3.py
- haarcascade_frontalface_default.xml
アプリ実行
今回はスピーカーなど別途必要なものはありません。
まずは、ターミナルで実行ファイルの位置へ移動します
cd /home/pi/workspace/ncappzoo/caffe/GenderNet
demo1
python3 demo1.py
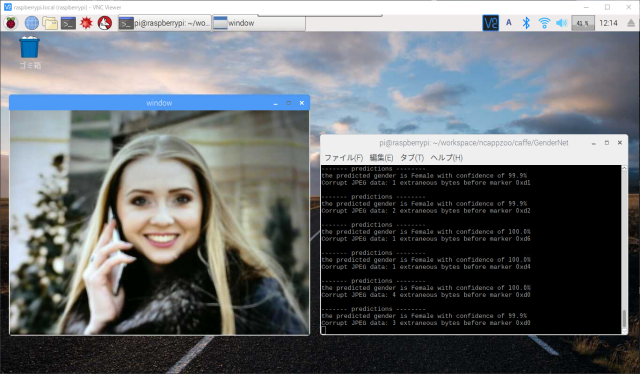
demo1.pyを実行すると、カメラ映像のウィンドウが開き、ターミナル側にはその映像に対するリアルタイム推論結果が文字で次々と表示されると思います。カメラ映像側のウィンドウで何かキーを押せばプログラムは終了します。
なお、何も実行されない場合は一旦 Ctrl + C キーで強制終了を行った後、もう一度実行してみて下さい。
本物の人物の顔をカメラに映すのが一番良いですが、近くに人が居ない場合はスマホやタブレットに顔画像を表示させて、そこにカメラを向けてみて下さい。
クラゲがデモで使っている画像について共有しますので、こちらも試してみて下さい。
https://photos.app.goo.gl/tqDSYoiRNr6XGj7j6
demo2
python3 demo2.py

demo2.pyを実行すると、フルスクリーンで画像が表示されます。左上にはカメラ映像が小さく表示され、その下に推論結果をテキスト表示していると思います。
認識精度は先程と同じですが、結果の表示にぐっと実用度が増したかと思います。
なお、今回用意している画像のサイズは1366×768です。ラズパイ画面の解像度も1366×768だと最適になるようになっています。
もし、うまく表示されていない場合は、ラズパイの解像度を変更(ラズパイ左上のラズパイアイコン > 設定 > RaspberryPiの設定 から変更できます)するか、画像のサイズを画像編集ソフトなどを使って変更してください。
ちなみに、現状のラズパイ画面の解像度を調べる場合は以下のコマンドを使います
tvservice -s
demo3
python3 demo3.py

demo3.pyは最初の動画と同じプログラムです。demo2.pyからの変化点として、顔に緑色の四角い枠が表示されているかと思います。demo3.pyは推論前に顔を検出し、検出した領域の画像のみを対象として推論を実行しています。そのため認識精度は先の2つよりも向上しています。
ソースコード解説
demo1
それではソースコードの解説です。run.pyから手を加えた箇所を説明します。
コードはこちらからも閲覧可能です。
https://github.com/electricbaka/movidius-ncs/blob/master/GenderNet/demo1.py
変更点は大きく3つです
- USBカメラでリアルタイム入力
- NCAPI v1 から v2 へ変更
- 関数消去などコードを整理
USBカメラでリアルタイム入力
USBカメラから映像をリアルタイム入力している箇所です。基本的には前回のGoogLeNetの改造と同じです。
#------------------------------# Capture#------------------------------cap = cv2#============================================================# Main Loop#============================================================while True:ret, frame = cap# Reload on errorif ret == False:continue# Wait keykey = cv2if key != -1:break# Displaycv2
前回との違いは、「映像読み込みが終わるまで待つ」という処理を加えている点です。コメントの"Reload on error" の部分です。
NCAPI v1 から v2 へ変更
こちらは機能や精度には関係ないのですが、古いAPIのままだと何となく気持ち悪いので、新しいAPIの記述へ変更しました。
#sys.path.insert(0, "../../ncapi2_shim")#import mvnc_simple_api as mvncfrom mvnc import mvncapi as mvnc#mvnc.SetGlobalOption(mvnc.GlobalOption.LOG_LEVEL, 2)mvnc#devices = mvnc.EnumerateDevices()devices = mvnc#ここは変更なしdevice = mvnc#device.OpenDevice()device#graph = device.AllocateGraph(blob)graph = mvncfifoIn, fifoOut = graph#graph.LoadTensor(img.astype(numpy.float16), 'user object')graph#output, userobj = graph.GetResult()output, userobj = fifoOut#ここは新規追加fifoInfifoOut#graph.DeallocateGraph()graph#device.CloseDevice()device
コメントで記述してある部分が元々run.pyで書かれたコードです。コメントの下に書いてるコードが変更後のコードです
関数消去などコードを整理
こちらも機能的には影響のない内容です。run.pyでは関数execute_graphを定義して使用していましたが、すっきりさせるために関数は消去しました
run.pyのプログラムをざっくり書くと以下のような構造になっています。
#ざっくりrun.pyデバイス準備モデルと重み読み込み推論実行静止画像読み込みexcute_graph実行結果表示
demo1.pyでは関数execute_graphの中身をセットアップ部とメインループ部に分けて書くことにより、関数を消去しています。
#ざっくりdemo1.pyデバイス準備モデルと重み読み込みwhile True:カメラ画像読み込み推論実行結果表示
その他の変更点として、重複していたり使っていないimportの削除、最後にメモリをお掃除するためのClean Up処理などを加えています。
demo2
続いてdemo2のソースコード解説です。demo1.pyから手を加えた箇所を説明します。
コードはこちらからも閲覧可能です。
https://github.com/electricbaka/movidius-ncs/blob/master/GenderNet/demo2.py
demo1からの主な変更点は以下です
- フルスクリーン表示
- Picture in Picture
- テキスト表示
フルスクリーン表示
フルスクリーンで表示させるための画像を2つ読み込みます
ラズパイ表示画面の解像度に合わせて画像サイズは1366×768です
img1 = cv2img2 = cv2
フルスクリーンを行うための準備を行います
nameWindowを使って第2引数に"cv2.WINDOW_NORMAL"を設定することと、setWindowPropertyを使って、第2引数に"cv2.WND_PROP_FULLSCREEN"、第3引数に"cv2.WINDOW_FULLSCREEN"を設定します。
第1引数はウィンドウの名前なので、任意の文字列でOK。
cv2cv2
デフォルト画像として全画面真っ黒表示にするために、黒画を用意します。numpy.zerosを使って値が0のndarryを作れば黒画ができます。ラズパイ表示画面の解像度に合わせたサイズにしています。
指定している数値は "高さ", "幅","カラーチャンネル数" です
img_out = numpy
実は、常に推論結果が得られるため、実際はこの黒画が使われることはありません。
ただ、プログラミング的に変数の初期値が無いと不安なのと、demo3では別の用途で活用するため用意しています。
推論結果によって表示する画像をif文を使って切り替えています
if predicted == 0:img_out = img1elif predicted == 1:img_out = img2
Picture in Picture
Picture in Picture、通称PinPは画像の中に小さな画像を表示させる機能の名称です。
ただし、OpenCVではそのような機能を持った関数はないため、直接ndarrayに処理を加えることで作成します。
img_camera = cv2img_display = img_out= img_camera
まず、カメラ映像frameを小さくするためにcv2.resizeを使って 400×300の画像img_cameraにします
次に推論結果によって表示する全体画像(ケーキ or クルマ)をimg_displayにコピーします
最後にimg_displayの一部をPython基礎で習ったスライスを使ってimg_cameraに置き換えています。始点の座標を(x, y)、幅をwidth、高さをheightとしたとき、以下のような指定になっています。
img_display [ y : y + height , x : x + width ]
テキスト表示
OpenCVで習ったcv2.putTextを使って、PinPの下にテキストを表示しています。
text = '%3.1f%%' % (100.0*) + ' ' +cv2
demo3
最後にdemo3について見てゆきましょう。認識精度を上げるために、カメラ画像全体を推論するのではなく顔領域のみを推論するようにしています。
コードはこちらからも閲覧可能です。
https://github.com/electricbaka/movidius-ncs/blob/master/GenderNet/demo3.py
セットアップ部で変数初期化や顔検出の準備を行っています。
img_face = img_outcounter = 0facerect = ()cascade = cv2
img_faceにはimg_outのコピーを代入、つまりデフォルトはnumpy.zerosで作成した黒画を流用します。
counterは初期値0を準備、facerectには空のタプルを準備しています。
cascadeにはcv2.CascadeClassifierを使って、顔検出用の分類器XMLファイルを読み込みます。
分類器の元ファイルはこちらにあります。
https://github.com/opencv/opencv/blob/master/data/haarcascades/haarcascade_frontalface_default.xml
今回使用する分類器は「正面の顔」ですが、他にも「目」や「体」「笑顔」など色々とあるようです。
カメラ画像から顔を検出して、検出された顔領域をfacerectに格納します
counter = counter + 1# Face detection only once in 10 timesif counter >= 10:facerect = cascadeprint(facerect)counter = 0
ここではcounterを使って10回に1回だけ顔検出を行っています。常に顔検出を行うと、検出部の領域変化が激しいためと処理を軽くするためです。回数はお好みで変えてもOKです。
cascade.detectMultiScaleでは4つの引数があります。
第1引数は入力画像
第2引数は、どれくらい細かく検出するかを設定します。 1.1程度で設定すると良さそうです。このパラメーターは処理時間にも影響します。参考リンク
第3引数は、検出した矩形領域が最低いくつ以上隣接している必要があるかを設定します。つまり検出が集中していない箇所はノイズとして無視するということです。値が小さいと見逃しは減少するが誤検出が増加、値が大きいと誤検出は減少するが、見逃しは増加します。参考リンク
第4引数は、検出した矩形領域の最小サイズの設定です。つまり検出できても小さな領域であればノイズとして無視するということです。
facerectには検出した顔の領域が複数入力されます。下の画像は複数の顔があった場合の検出イメージです。
全く検出されなかった場合は引き続き前回のimg_faceをそのまま使い、少しでも検出された場合は最も大きな顔領域(上のイメージだと一番右の領域)を新たなimg_faceとして更新します。
if > 0:print("face detected!")face_height =index_max = numpyrect =img_face =cv2
"facerect[:,3]" は 検出領域の「高さ」だけを要素に持つリストです。face_heightにこのリストが入ります。
argmaxを使って、最も「高さ」が大きいリストのインデックスを取得し、index_maxへ代入します
検出される領域の「幅」と「高さ」は同じです。結果として、変数rectには最も大きな顔領域が入ることになります。rectの中身は以下の通りです。
rect[0]:矩形領域の左上x座標,
rect[1]:矩形領域の左上y座標,
rect[2]:矩形領域の幅
rect[3]:矩形領域の高さ
img_faceにスライスを使って顔領域の画像のみを入れます。要素の指定はPinPのときと同じ要領です。
最後にframeに対し、顔領域の四角形を描画します。cv2.rectangleを使って、座標はタプル化して指定しています
今回はGenderNetだけでしたが、AgeNetでも同様に出来ますし、GenderNet + AgeNetの両方に挑戦してみるのも面白いと思います。
次回は物体検出を行うSSD/Yoloの実行です!
以上、「GenderNetで性別リアルタイム推定&画像出力」でした。