2018/08/17
【08.実践2】NCAPIとGoogLeNet画像認識の解説

どうも、ディープなクラゲです。
「ゼロから学ぶディープラーニング推論」シリーズの8回目記事です。
このシリーズでは、Neural Compute StickとRaspberryPiの使い方をゼロから徹底的に学び、成果としてディープラーニングの推論アプリケーションが作れるようになることを目指しています。

第8回目は、NCAPIと前回実行したサンプルコードの解説を徹底的に行います。
【 目次 】
- NCAPIを学ぶ
- GooLeNetソースコード解説
NCAPIを学ぶ
まず、今回のサンプルソース全体の流れに大きく関わるNCAPIについて簡単に説明します。
NCAPIとは、Neural Compute Stickでディープラーニング推論を実行させるためのAPIです。
なお、「Python基礎」「NumPy」「OpenCV」と違って「NCAPI」は Movidius Neural Compute Stickのみにしか使えないAPIですので、以下の説明は無理に覚える必要はなく、さらっと流す程度の理解でOKです。
こちらのサイトに概要が書かれていますが、ここではより簡単に図を交えて説明したいと思います。
https://movidius.github.io/ncsdk/ncapi/ncapi2/py_api/readme.html
簡単に推論の概要を図でイメージに表すとこんな感じです。
graphにはディープラーニング学習済みのモデルと重みが紐づいています。つまりgraphは学習済みAIそのものです。
inputはエレキギターやネコなどの画像です。それをgraphに通すとoutputに推論結果が格納されるという流れです。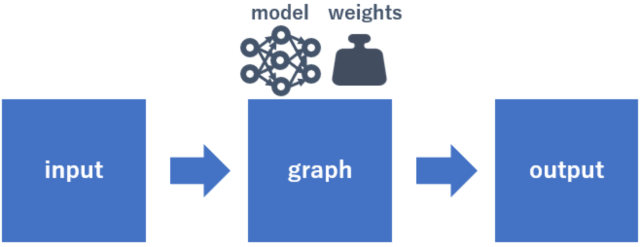
実際のプログラムでは、上記に加えて「pre-precess」「FIFO」「device」「blob」という登場人物が加わります。
画像はそのまま入力するとエラーになってしまうため、リサイズや型変換などが事前に必要で、その処理が「pre-process」と呼んでいます。
「FIFO」は"First In First Out"という方式のバッファメモリのことで、それぞれ入力用と出力用に用意が必要です。
「device」はNeural Compute Stickのことで、複数台接続している場合、graphをどのNeural Compute Stickで扱うか、紐づけさせるために存在しています。
「blob」は学習済みのモデルと重みデータです。
これらの登場人物を加えたイメージ図を以下に示します。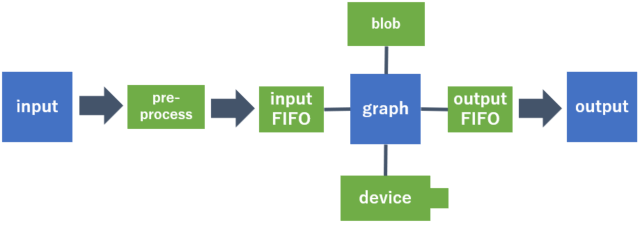
実際のプログラムの処理の流れとしては、以下のようになります。
- Device準備
- Graph準備
- Graphの割り当て
- 入力画像準備
- 推論実行
- 推論結果取得
- 後片付け
Device準備
Deviceとは先程の説明の通り、ラズパイに挿入しているNeural Compute Stickそのものです。
これをプログラムに認識させて、初期設定を行い、通信の準備を行います
Graph準備
メインとなるGraphを準備します。
Graphの割り当て
推論させるために必要である「input FIFO」と「output FIFO」を用意し、
「graph」を「blob」「device」「input FIFO」「output FIFO」のそれぞれと紐づけます。
入力画像準備
graphで正しく推論させるために入力画像を整形します。
画像のリサイズ、型変換、正規化を行います
推論実行
上記の「入力画像」を「input FIFO」に入力すると「output FIFO」にデータが現れます
推論結果取得
「output FIFO」に現れたデータを取得します
後片付け
プログラム終了直前に「input FIFO」「output FIFO」「graph」「device」を破棄します。
以上がNCAPIを使った処理の流れですが、何となく理解できればOKです。
GooLeNetソースコード解説
それでは、先程のNCAPIを踏まえて、GoogLeNetの run.py の中身を徹底的に見てゆきましょう!
#! /usr/bin/env python3
これはPython基礎「先頭行の #!」 で説明した通りです。このコードから分かる事はpython3で実行した方が良いということです。
"python3 run.py"で実行している限りは、このコードは無くても大丈夫です。
from mvnc import mvncapi as mvncimport sysimport numpyimport cv2import timeimport csvimport osimport sys
ここでは各モジュールをimportしています
mvncはモジュールが集まったパッケージです。ここからmvncapiというモジュールを取り出してします。
本来なら、mvncapi.関数名 というように使いますが、今回は as mvnc となっているので、mvnc.関数名 と少しだけ短縮した名前で使えるという事です。
このプログラムで使われているモジュールは、mvncapi、numpy、cv2だけです。
sys、time、csv、osはimportされていますが、実際には使われていません。
また、import sysが重複しているのは誤記かと思われます。
dim=(224,224)
変数dimにタプルを代入しています。
読み込んだ画像ファイルをリサイズするときに使います。
EXAMPLES_BASE_DIR='../../'
変数EXAMPLES_BASE_DIRに文字列'../../'を代入しています。
Linuxコマンドの cd で 'cd ..' は1つの上のディレクトリに戻るという意味でした。
つまり '../../' は2つ上のディレクトリを指します
# ***************************************************************# get labels# ***************************************************************labels_file=EXAMPLES_BASE_DIR+'data/ilsvrc12/synset_words.txt'labels=numpy
最初の3行はコメント文です。
変数labels_fileに 文字列 '../../data/ilsvrc12/synset_words.txt' を入力しています。
「Numpy」で習った numpy.loadtxtを使って、label_fileのテキストファイルからTabを区切り文字としたリストを変数labelsに代入しています。
このテキストファイル、実際にnanoで開いてみましょう
nano ~/workspace/ncsdk/examples/data/ilsvrc12/synset_words.txt
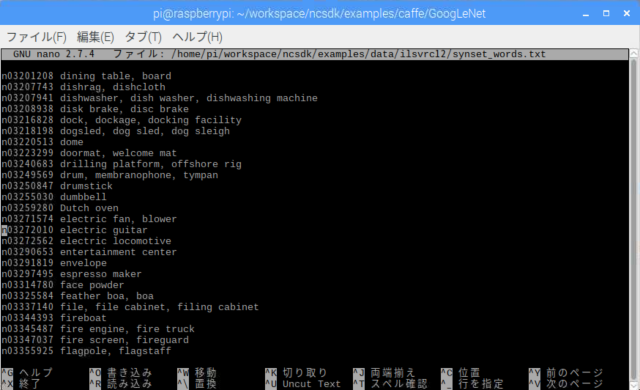
推論で分類する全ての対象物リストです。全部で1000データあります。
例えば、インデックス546の文字列は print(labels[546]) で "n03272010 electric guitar" と表示させることが出来ます。
再びサンプルソースに戻ります。
# ***************************************************************# configure the NCS# ***************************************************************mvnc
NCAPIの関数です。
エラーログをどこまで出すかを設定しています。
エラーログには「致命的なエラー」「通常エラー」「ワーニング」「情報」「デバグ用情報」があります。
2 という設定は「情報」と「デバグ用情報」を除いた エラーログだけを出す設定です。
そもそもデフォルト設定が2なので、この行はあっても無くても同じです。
細かく説明しましたが、特にディープラーニング推論には影響ないので、さらっと流してもらって良いです。
# ***************************************************************# Get a list of ALL the sticks that are plugged in# ***************************************************************devices = mvncif == 0:print('No devices found')
「NCAPI」で説明した「Device準備」です
mvnc.enumerate_devicesは、ラズパイに接続されているNeural Compute Stickを認識してリスト化します。
認識できない場合はリストの要素数は0です。認識できた場合は、認識した数に応じた要素数になります。
このブロックでは、リストの要素数が0の場合、'No devices found'という文字列を表示してquit()、つまりプログラムを終了します。
実際にラズパイからNeural Compute Stickを外した状態で run.py を実行すると上記の表示が出ますので試してみて下さい。
# ***************************************************************# Pick the first stick to run the network# ***************************************************************device = mvnc
「NCAPI」で説明した「Device準備」の続きです
先程のmvnc.enumerate_devicesにて、複数のNeural Compute Stickがラズパイに接続されている場合、一番初めに認識したものがリストdevice[0]に入っています。
ここでは、device[0]に入っているものでクラスのインスタンスを生成しています。
いきなり、「クラス」とか「インスタンス」という言葉が出てきて、戸惑った方もいると思います。
ここではあまり深く考えずに、変数deviceを最初に認識したNeural Compute Stickで初期設定したと考えておけばOKです。
これ以後では、device.関数 を使うことが可能になります。
# ***************************************************************# Open the NCS# ***************************************************************device
「NCAPI」で説明した「Device準備」の続きです
device.openでNeural Compute Stickと通信開始です。
network_blob='graph'
変数network_blobに文字列'graph'を代入しているだけです。
この'graph'は、現在のGoogLeNetのフォルダ内にあるファイル名です。拡張子はありません。
この'graph'にGoogLeNetのモデルと重みの情報が入っています。
#Load blobwith as f:blob = f
「Python基礎」その他で学習した形です。変数 blob にモデルと重みの情報が入ります。
graph = mvnc
「NCAPI」で説明した「Graph準備」です
'graph'という名前でGraphクラスのインスタンスを生成しています。
これ以後では、graph.関数 を使うことが可能になります。
fifoIn, fifoOut = graph
「NCAPI」で説明した「Graphの割り当て」です
第一引数はどのDeviceを使うのか、第二引数はモデルと重み情報データです。
それぞれ、"device"と"blob"を指定しています。
「input FIFO」として"fifoIn"、「output FIFO」として"fifoOut"が生成され、"graph"に割り当てられました。
# ***************************************************************# Load the image# ***************************************************************ilsvrc_mean = numpy #loading the mean file
numpy.load(EXAMPLES_BASE_DIR+'data/ilsvrc12/ilsvrc_2012_mean.npy') は「NumPy」その他で説明した np.load を使ってファイル "ilsvrc_2012_mean.npy" を読み込んでいます。
このファイルは一体何かというと、ディープラーニング学習時に学習させた画像データの平均画像です。
この平均画像は3次元配列で、形状は(3, 256, 256)です。分かりやすくいうと、256x256の画像が3枚あると想像してください。3枚はそれぞれ、Blueだけの画素、Greenだけの画素、Redだけの画素で構成されています。
後半の .mean(1).mean(1)は、「NumPy」その他で説明した np.mean を使った配列要素の平均を求める関数です。
結果的に ilsvrc_mean は1次元配列で形状は(3,)です。つまり値が3つだけの配列です。それぞれの値は、全Blue画素の平均値、全Green画素の平均値、全Red画素の平均値ということになります。
img = cv2
cv2.imreadは「OpenCV」の関数です。「OpenCV」は次回行うのでまだ習っていませんが、この関数について簡単に説明します。
このコードは "nps_electric_guitar.png" というエレキギター画像ファイルを読み込んで 変数 img に代入するという意味です。
img=cv2
cv2.resizeも「OpenCV」の関数です。今回のソースコードで出てくる「OpenCV」の関数はこの2つだけです。これも簡単に説明します。
変数 img に入っている画像を変数 dim の縦横サイズにリサイズするという意味です。
dimは(224,224)でしたので、224x224の画像にするということになります。
ただし、元のエレキギター画像の配列は3次元で、形状は(813, 800, 3)です。
縦横のみ(224,224)の形状に変更したので、結果的には(224, 224, 3)という形状になっています。
平均画像と考え方は同じです。224x224の画像が3枚あると想像してください。3枚はそれぞれ、Blueだけの画素、Greenだけの画素、Redだけの画素で構成されています。
img = img
astypeは「NumPy」で学びました。強制的にデータ型を変換させる関数です。
img配列の全要素を float32 の型に変換したという意味になります。
= ( - )= ( - )= ( - )
これもややこしい感じの記述ですが、落ち着いて観察すると分かります。
コロンは「NumPy」で学んだスライスです。
img[:,:,0] は エレキギター画像の224x224の画像1枚で、Blueだけの画素です。
img[:,:,1] は エレキギター画像の224x224の画像1枚で、Greenだけの画素です。
img[:,:,2] は エレキギター画像の224x224の画像1枚で、Redだけの画素です。
ilsvrc_mean[0] は 平均画像の全Blue画素の平均値です。
ilsvrc_mean[1] は 平均画像の全Green画素の平均値です。
ilsvrc_mean[2] は 平均画像の全Red画素の平均値です。
つまり、Blue,Green,Redそれぞれに対し、エレキギター224x224画像の全ての画素から平均画像の平均値を一律でマイナスしているという意味になります。
caffeのモデルを使って推論するには、このように前処理で平均画像を引くことが暗黙のルールになっています。この前処理は正規化と呼ばれています。
これで入力画像準備が完了しました。
# ***************************************************************# Send the image to the NCS# ***************************************************************graph
「NCAPI」で説明した「推論実行」です
引数3つは「input FIFO」「output FIFO」「前処理済みの入力画像」です。
最後の引数は、任意の名称を付けることができますが、特に重要ではありません。
# ***************************************************************# Get the result from the NCS# ***************************************************************output, userobj = fifoOut
「NCAPI」で説明した「推論結果取得」です
outputに推論結果が入ります。
userobjには先ほどの任意の名称 'user object' が入っています。
outputの中身について、もう少し詳しく見ていきましょう
outputの形状は(1000,) つまり要素数1000個の1次元配列です。
それぞれの要素には何が入っているかというと、入力画像に対する推論後の確率が入っています。
例えば、output[546] には 0.996 という数値が入っています。リストoutputは最初の方で取得したリスト labels と紐づいています。
labels[546]の中身は "n03272010 electric guitar" でした。つまり、この結果が意味することは electric guitar(エレキギター)である確率が 0.996 であるということです。
他の要素も見てみると、output[545]は 0.0 で labels[545]は "n03271574 electric fan, blower" です。つまり、electric fan(扇風機)である確率が 0.0 であるということを示しています。
このように、outputとlabelsは紐づいていて、labelsに書かれている1000種類の全てに対する確率が計算され、outputに値が代入されています。
# ***************************************************************# Print the results of the inference form the NCS# ***************************************************************order = output
これは「NumPy」ソートで習った形です。
output.argsort() で確率を昇順に並べたインデックスのリスト
output.argsort()[::-1] で確率を降順に並べたインデックスのリスト
output.argsort()[::-1][:6] で確率を降順に並べたとき、上位6位までのインデックスリスト
という意味で、これを変数orderに代入しています。
print('\n------- predictions --------')
"\n" は改行を意味します。その他は文字列表示しているだけです。
for i in :print ('prediction ' + + ' (probability ' + + ') is ' + + ' label index is: ' + )
「Python基礎」で習ったfor in です。
iを0~4まで1ずつ変化させ、printを繰り返しています。
strは「Python基礎」で習った型変換です。数値を文字列に変換しているだけです。
i は 0~4 までの順位を表します
output[order[i]] は i の順位にあるモノの確率を表しています
labels[order[i]] は i の順位にあるモノの名前を表しています
order[i] は i の順位にあるモノのインデックス値を表しています
このようにして、入力画像に対する上位ベスト5の推論結果を表示しています。
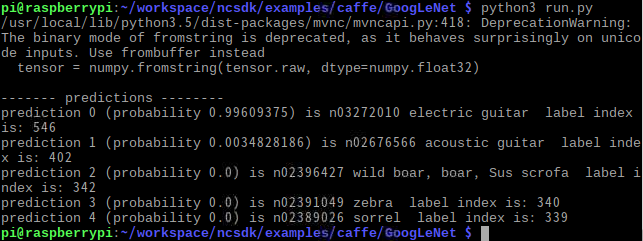
推論結果表示
# ***************************************************************# Clean up the graph and the device# ***************************************************************fifoInfifoOutgraphdevice
「NCAPI」で説明した「後片付け」です
最後、プログラム終了前に、無駄なメモリや通信は破棄しておきます。
以上で、GoogLeNet画像認識のソースコードはおしまいです。大変お疲れさまでした!
今回はサンプルソースコードの中身をじっくり見ました。これを改造してUSBカメラでリアルタイムに推論できるようにしたいと思います。
次回はカメラ映像を主に扱う「OpenCV」について学びます。
以上、「NCAPIとGoogLeNet画像認識の解説」でした。