2018/06/27
【01.概要】Neural Compute Stickで始めるディープラーニング

どうも、ディープなクラゲです。
今回から「ゼロから学ぶディープラーニング推論」シリーズを掲載してゆきます!
このシリーズは、Neural Compute StickとRaspberryPiの使い方をゼロから徹底的に学び、成果としてディープラーニングの推論アプリケーションが作れるようになることを目指します。

第1回目は、主に全体概要やディープラーニングそのものについての説明を行います
推論アプリを作るにあたり、ディープラーニングの基礎全てを理解している必要は全くありません。ディープラーニングについて調べると、良く分からない式や難しそうな用語がたくさん出てきて挫折しがちですが、今回そのようなモノを無理に詰め込む必要はないです。
ここに書いてあることが何となく分かればOKです。
【 目次 】
- 全体概要
- どんなモノが出来る?
- Neural Compute Stickとは
- AI(人工知能)とは
- ディープラーニングの種類と用途
- ディープラーニングのフレームワーク
- ディープラーニングのフェーズ(学習、推論)
- ディープラーニングの数学、専門用語
- ディープラーニングのプログラミング
- ディープラーニングの環境構築
全体概要
現在、たくさんのディープラーニング技術情報が溢れていますが、数式や専門用語、プログラミング、フレームワーク、環境構築など、理解しなければならい項目が多く、初心者にとってはどこから始めて良いかも分からず、ハードルが高いのが現状です。
| 項目 | 具体例 |
|---|---|
| 種類 | CNN, RNN, GAN, DQN |
| 用途 | 画像認識、自然言語処理、時系列データ予測、画像生成、強化学習 |
| フレームワーク | Tensorflow, Keras, chainer, caffe, PyTorch, Theano etc |
| フェーズ | 学習データ作成、学習、推論 |
| 数学 | 線形代数(ベクトル、行列)、微分(偏微分) 、確率・統計 |
| 専門用語 | パーセプトロン、ニューラルネットワーク、隠れ層、活性化関数、損失関数、誤差逆伝播 etc |
| プログラミング | Python, NumPy, MATLAB, R, C/C++ |
| 環境構築 | Anaconda, Jupyter Notebook, cuDNN, Docker |
各項目については、この後詳しく説明しますが、まずはズバッと斬ります。
研究者を目指すのであれば数学や専門知識がきっちりと必要ですが、技術を使いこなすエンジニアであれば、理論を理解することよりも実践的な内容から始めた方が近道です。また幅広く何でも学ぶのではなく、まずは1つに集中した方がよいです。
ということで、本シリーズでは理解し易く応用に繋がるディープラーニング「推論」を学び、「画像認識」に集中します。
実行環境は「Neural Compute Stick」と「RaspberryPi」を使い、カメラでリアルタイムに画像認識を行う小さくて安価な人工知能を作り出します!

本シリーズでは全15回程度の記事を通して、Neural Compute Stickを使ったディープラーニング推論について、徹底的に詳しく解説します。
また、RaspberryPiやPythonについても初心者向けに徹底解説します。
お手元にNeural Compute StickとRaspberryPiなどをご用意していただき、一緒にゼロから開発してゆきましょう!
※具体的に何が必要なのでどこで買えば良いのかは次回の記事で徹底解説します。
どんなモノが出来る?
さて、気になるのはこのシリーズに付き合うと一体何ができるのか?ということだと思います。
「結局、mnistやって終わりかよ!」では意味がありません。
ちなみにmnist(エム二スト)とはディープラーニングのHello, worldです。
こちらの動画を見て下さい
これと同じものが理解して作れるようになります。
主に以下の3つです
- 画像を認識して音を出力
- 性別を認識して画像を出力
- 物体認識を応用したAR出力
全てUSBカメラを使ってリアルタイムにディープラーニングの推論を行い、その結果をアプリケーションに繋げているのが特徴です。
このようなアプリを作ることにより、ディープラーニングでは何が得られて、どのくらいの精度なのかが身をもって体感できます。書籍や講義では得られない、「ディープラーニングで出来ること・出来ないこと」を感じ取りましょう!
Neural Compute Stickとは
USB端子を搭載したスティックで、ディープラーニング推論処理を高速化するアクセラレータです。アクセラレータとは処理能力を高めるために追加して利用するハードウェアのことです。

これ単体で使うものではなく、RaspberryPiやLinux搭載PCに挿入して使います。
クラウドを利用することなくエッジ側だけでリアルタイムに推論できます。エッジというのは、今回の場合RaspberryPiやLinux搭載PCを指します。ホストコンピューターとも呼びます。
Neural Compute StickはインテルMovidiusが開発した専用チップ「Myriad 2」 を搭載しています。
「Movidius」は元々の企業名で、2016年にインテルに買収されています。
「Myriad 2」は高性能かつ低消費電力な画像処理ユニットで、ジャスチャー制御できるドローンやスマートセキュリティカメラなどへの搭載実績があります。
実際に使うときは、Neural Compute Stick SDK(NCSDK)をホストコンピューターにインストールが必要です。インストールに関しては別の回に徹底的に説明します。
また、CaffeやTensorflowで生成したモデルや重みをMovidius用に変換するための「SDK Tools」というツールも用意されています。
「Caffe」、「Tensorflow」、「モデル」、「重み」についてはこの後説明します。
ぶっちゃけ、RaspberryPiとUSBカメラさえあれば、ディープラーニング推論は可能です。
ただし、リアルタイムに推論を行うと遅過ぎてイライラすると思います。
また、本コンテンツで説明しているコードは、Neural Compute Stick専用のソースコードですのでNeural Compute Stickを購入することをお勧めします。
AI(人工知能)とは
最近よくニュースで「AI」「人工知能」という言葉が良く使われていますが、実は明確な定義がないのが現状です。
例えば、昔から既にある「ある温度以上になったら、自動的に冷房をONするエアコン」も人工知能と言えます。
クラゲの独断で、人工知能について以下の3種類に分けました
- 条件分岐を使ったAI
- 機械学習を使ったAI
- ディープラーニングを使ったAI
例えば、それぞれの人工知能で、猫と犬の画像を判別する超簡易的なAIを作る場合のイメージを書きます。
(※あくまでイメージですのでご注意ください)

1.条件分岐を使ったAI
それぞれの目と鼻を抜き出し、目の面積が鼻の面積の1.5倍以上なら猫、それ以下なら犬という風に判別します。
1.5倍という数値は人がデータから検討した結果の値です。
条件分岐AIは全て人が設計を行っているのが特徴です。
先程のエアコンはこのAIに相当します。現状の一般的なソフトウェアで使われているプログラミングもここに当たります。
2. 機械学習を使ったAI
それぞれの目と鼻を抜き出し、「面積データ」と「犬/猫の正解タグ」をセットとしたデータを集め、何等かの相関関係がないかをコンピューターに計算させます。
そして、コンピューターが以下のような公式を自動的に弾きだすのが機械学習です。
猫である確率 = f (鼻の面積, 目の面積)
機械学習は、途中までの特徴抽出は人間が行いますが、細かな相関関係のある式を見つけ出すのはコンピュータの役目となります。
3. ディープラーニングを使ったAI
何も抜き出さず「画像丸ごとデータ」と「犬/猫の正解タグ」をセットとしたデータを大量に集め、何等かの相関関係がないかをコンピューターに計算させます。
そして、コンピューターが以下のような公式を自動的に弾きだすのがディープラーニングです。
猫である確率 = f (画像まるごと)
ディープラーニングは、端的に言うと、人が介入することなく全てコンピューターのみで式を見つけ出すことができるのが特徴です。
そのため、式を見ても、一体何に注目して猫である確率を決めたのかが分かりづらい(ブラックボックス)ことと、膨大な画素情報から相関関係を見つけるために大量の画像データ数が必要となるというデメリットもあります。
ディープラーニングの考え方は昔からありましたが、コンピューターの計算能力が追い付かず実用的に使い物になりませんでした。ここ数年でのコンピュータ性能が一気に向上していることもディープラーニングを押し上げた要因の一つだと思います。
これ以降は、ディープラーニングについて掘り下げていきます。
※実際には人の介入はゼロではありません
ディープラーニングの種類と用途
ディープラーニングの種類として主に以下4つが挙げられます。これらはディープラーニングのネットワークと呼ばれるものです。
「ネットワーク」とは「手法」という意味で捉えておけばOKです。
- CNN(Convolutional neural network)
- RNN(Recurrent Neural Network)
- DQN(Deep Q-Network)
- GAN(Generative Adversarial Network)
それぞれのネットワークは得意な用途を持っています。何が得意なのかを以下に記します。
CNN:画像認識
ディープラーニングで最も精度が高いのが画像認識です。人の眼の精度を超えたとされています。既に工場の目視検査や医療の画像診断などに活用されています。物体認識と呼ばれる技術では、例えばクルマや人がたくさん映っている画像も認識できて、クルマや人それぞれの領域を示すマーキングを行うことも可能です。
本コンテンツではCNNによる画像認識を取り扱います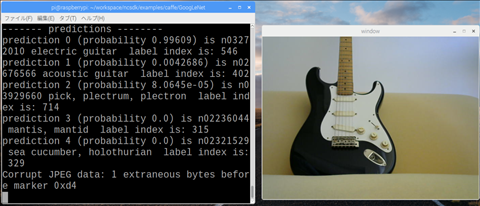
RNN:自然言語処理
音声認識や外国語の翻訳などです。数年前にGoogole翻訳が飛躍的に向上したのはディープラーニングによるためと言われています。RNNの進化版としてLSTMというアルゴリズムもあります。RNNやLSTMは他にも株価予測や売上予測など時系列データの予測にも使われています。DQN:強化学習
強化学習とは簡単にいうと、赤ちゃんのように学習する行為です。赤ちゃんは限られた環境の中で様々な動きにチャレンジして成功と失敗を繰り返して、だんだんと学習してゆきます。強化学習の代表例はGoogleが開発し、世界ランク一位のプロ囲碁棋士を破ったAlphaGo(アルファ碁)です。クルマやドローンなどの自動運転技術にも使われています。GAN:画像生成
ここで言う画像生成とは、画像の特徴を捉えて、似たような画像を作り出すものです。
例えば、猫の画像をゴッホ風にしたり、テキストから画像生成を行うということが出来ます。
ディープラーニングのフレームワーク
「フレームワーク」とは簡単にいうと「ライブラリ」の進化版で、その名の通り枠組みです。
一連の処理の流れが出来ている枠に、ユーザーが詳細設定を加えるだけで、ディープラーニングが出来てしまうということです。
もちろん、フレームワークを使わずに、1からプログラムを書くことも可能ですが、その場合は数学の知識が必須となります。

ディープラーニングのフレームワークはありがたいことに、無料で公開されており、誰でも使うことができます。
代表的なフレームワークをいくつか挙げます
- Tensorflow
- Caffe
- PyTorch
- Chainer
etc
現状最も使われているのはGoogleが開発した「Tensorflow」かと思われます。
Neural Compute Stickで対応しているフレームワークは「Tensorflow」と「Caffe」です。
サンプルソースコードとしては、先行して開発されたCaffeの方が現状は充実していますし、Caffeは画像認識を最も得意としています。また、ディープラーニング「推論」においては、フレームワークによる差は少なく、後で別のフレームワークに乗り換えて推論を行うことは容易です。
以上の理由から、本コンテンツでは、Caffeを利用したディープラーニング推論を行います。
ディープラーニングのフェーズ(学習、推論)
さあ、ここで何度も登場してきている「推論」について説明します。
クラゲはディープラーニングのフェーズを以下の3つに分類しました
- 学習データ作成
- 学習
- 推論
学習データ作成
「学習データ作成」は学習させるためのデータを作成するフェーズです。先程の犬と猫の画像を判別するディープラーニングであれば、「犬」の画像と「猫」の画像を大量に用意します。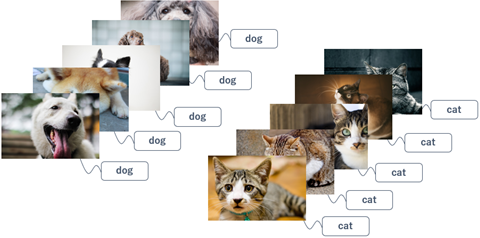
このときのデータの質と量が、ディープラーニングの性能に大きく影響を及ぼします。
必要となるデータは、最終的にどのような状況で犬猫を判別したいかによります。例えば、常に顔をアップしたときの画像だけを判別すれば良いのか、全体像が映っている画像だけを判別すれば良いのか、常に背景が決まっているような画像の判別で良いのか、様々な背景でも判別したいのか、などなど目的に応じて学習させるための画像データを用意することが必要です。
また、それぞれのデータに正解のタグ付け(犬or猫)をしておく必要があります。
ここまでは、特にフレームワークは使いません。人手による作業がメインとなる場合が多いです。
ちなみに、Web上にはデータセットと呼ばれる学習データも無料公開されています。実験や研究目的であれば、これらのデータを活用します。
学習
画像認識におけるAIを簡単に図式化すると以下のようになります。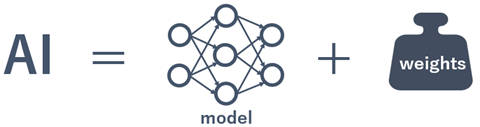
つまり、AIは「モデル(model)」と「重み(weights)」の組合せで構成されています。
「モデル」と「重み」さえ分かってしまえばAIが完成するということです。
「モデル」はネットワークです。複数の層を組み合わせてネットワークを作りますが、層の数を増やせば増やすほどより複雑な学習が可能となる一方、計算処理に多くの時間が必要となります。
「モデル」は人が設計します。先のフレームワークを使ってコードを書きますが、ある程度テンプレートは決まっているので、細かな詳細設定を行うことがメインとなります。
「重み」は何を認識させたいかによって変わるパラメーターです。
「重み」は、「学習データ」と「モデル」を使って計算させることによって求まります。この過程がまさに「学習」フェーズとなります。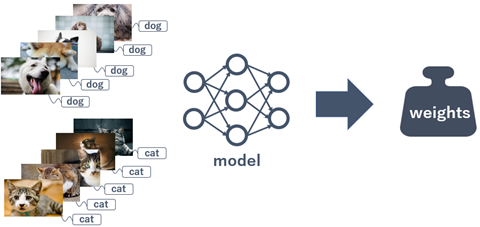
「重み」はコンピューターが計算しますが、この計算処理は非常に膨大です。
どれくらい時間がかかるかは、コンピューターの性能とモデルの深さと学習データ量次第です。「GPU」を使うと処理が速くなります。
計算が終わると「重み」を得ることが出来ます。
推論
ディープラーニングの「推論」とは、学習したデータ以外の画像を使って、実際に犬猫を予測させるフェーズです。
学習時に得た「モデル」と「重み」に画像を入力すると、予測結果を出します。このときの計算処理は比較的軽く、リアルタイムに予測結果を出すことも可能となります。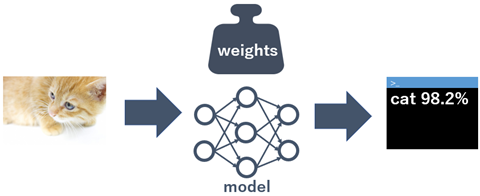
ディープラーニングの数学、専門用語
ディープラーニングをwebで調べると以下のような数学知識や専門用語の理解が必要そうに見えます。
| 項目 | 具体例 |
|---|---|
| 数学 | 線形代数(ベクトル、行列)、微分(偏微分) 、確率・統計 |
| 専門用語 | パーセプトロン、ニューラルネットワーク、隠れ層、活性化関数、損失関数、誤差逆伝播 etc |
研究レベルでディープラーニングを行いたい方は数学知識と専門用語の理解が必須でしょう。
一方で、ディープラーニングを使いこなすレベルであれば、数学知識は無くても出来ますし、専門用語の理解はそこそこでOKです。
さらに、まずは「推論」だけを学ぶのであれば、両方ともほぼ不要です。知っておくべきことは、学習時に得た「モデル」と「重み」を使って予測結果を出すという流れだけです。
ディープラーニングのプログラミング
webで調べると良く出てくるプログラミングとして以下のものが挙げられます。
- Python
- NumPy
- MATLAB
- R
- C/C++

現状、ディープラーニングを行うにあたり、クラゲがお勧めする言語は「Python」です。
理由は世界で圧倒的に使われているからです。圧倒的に使われているために情報量も多いですし、Pythonはプログラムとしてもシンプルで非常に書きやすいのが特徴です。
ちなみに「NumPy」はプログラミング言語ではなくPythonのライブラリです。Numpyの1部も必要です。
ディープラーニングの環境構築
webでディープラーニングの環境を調べると以下のような単語が出てくると思います。
ディープラーニングで学習を行う際は、ここら辺を検討した方が良いでしょう
- Anaconda
- Jupyter Notebook
- cuDNN
- Docker
- Google colaboratory
etc
しかし、今回はディープラーニングの推論です。
基本的に推論を行うだけであれば、上記の検討は不要です。
Neural Compute Stickを使う場合は、専用の「NC SDK」が用意されていますので、これ1つだけインストールすれば環境はOKです。
具体的なインストール方法については、別の記事で詳細を書きます!
以上、「Neural Compute Stickで始めるディープラーニング」の概要でした。